 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Structures Mining with Contrastive Modality Fusion for Multimedia Recommendation
Paper and Code
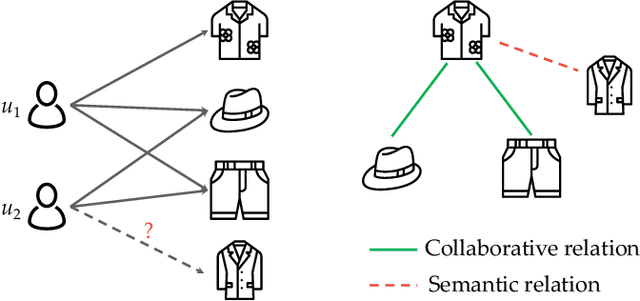



Recent years have witnessed growing interests in multimedia recommendation, which aims to predict whether a user will interact with an item with multimodal contents. Previous studies focus on modeling user-item interactions with multimodal features included as side information. However, this scheme is not well-designed for multimedia recommendation. Firstly, only collaborative item-item relationships are implicitly modeled through high-order item-user-item co-occurrences. We argue that the latent semantic item-item structures underlying these multimodal contents could be beneficial for learning better item representations and assist the recommender models to comprehensively discover candidate items. Secondly, previous studies disregard the fine-grained multimodal fusion. Although having access to multiple modalities might allow us to capture rich information, we argue that the simple coarse-grained fusion by linear combination or concatenation in previous work is insufficient to fully understand content information and item relationships.To this end, we propose a latent structure MIning with ContRastive mOdality fusion method (MICRO for brevity). To be specific, we devise a novel modality-aware structure learning module, which learns item-item relationships for each modality. Based on the learned modality-aware latent item relationships, we perform graph convolutions that explicitly inject item affinities to modality-aware item representations. Then, we design a novel contrastive method to fuse multimodal features. These enriched item representations can be plugged into existing collaborative filtering methods to make more accurate recommendations. Extensive experiments on real-world datasets demonstrate the superiority of our method over state-of-the-art baselines.