 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Training System for 100-Million Classification at Alibaba
Paper and Code
Feb 09, 2021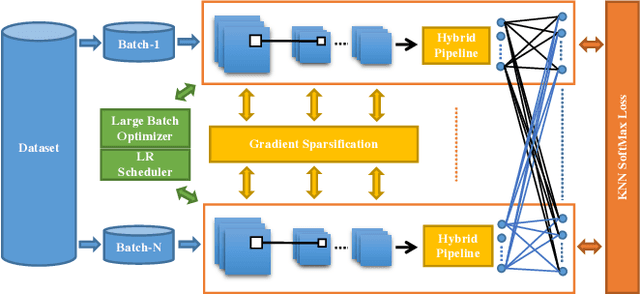
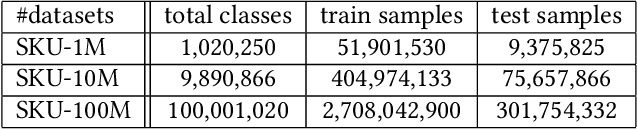
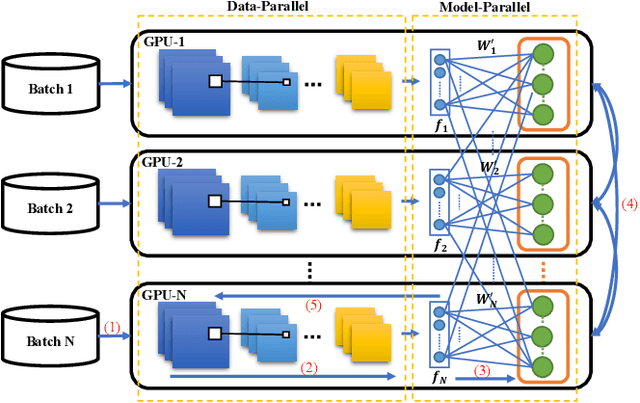
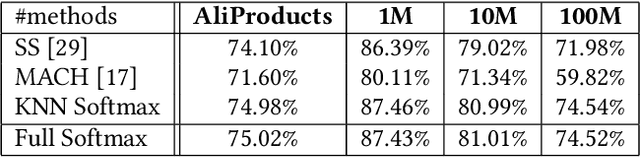
In the last decades, extreme classification has become an essential topic for deep learning. It has achieved great success in many areas, especially in computer vision and natural language processing (NLP). However, it is very challenging to train a deep model with millions of classes due to the memory and computation explosion in the last output layer. In this paper, we propose a large-scale training system to address these challenges. First, we build a hybrid parallel training framework to make the training process feasible. Second, we propose a novel softmax variation named KNN softmax, which reduces both the GPU memory consumption and computation costs and improves the throughput of training. Then, to eliminate the communication overhead, we propose a new overlapping pipeline and a gradient sparsification method. Furthermore, we design a fast continuous convergence strategy to reduce total training iterations by adaptively adjusting learning rate and updating model parameters. With the help of all the proposed methods, we gain 3.9$\times$ throughput of our training system and reduce almost 60\% of training iterations. The experimental results show that using an in-house 256 GPUs cluster, we could train a classifier of 100 million classes on Alibaba Retail Product Dataset in about five days while achieving a comparable accuracy with the naive softmax training process.