 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Paper and Code
Sep 11, 2019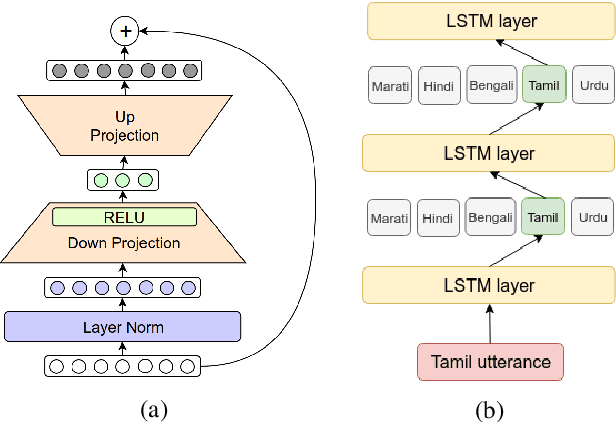
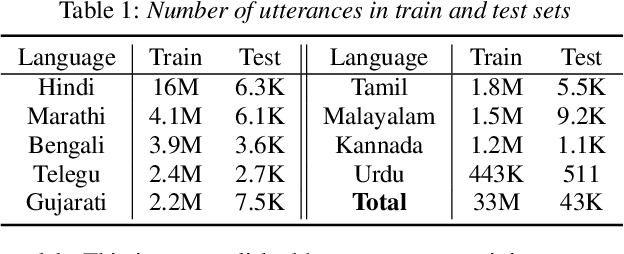
Multilingual end-to-end (E2E) models have shown great promise in expansion of automatic speech recognition (ASR) coverage of the world's languages. They have shown improvement over monolingual systems, and have simplified training and serving by eliminating language-specific acoustic, pronunciation, and language models. This work presents an E2E multilingual system which is equipped to operate in low-latency interactive applications, as well as handle a key challenge of real world data: the imbalance in training data across languages. Using nine Indic languages, we compare a variety of techniques, and find that a combination of conditioning on a language vector and training language-specific adapter layers produces the best model. The resulting E2E multilingual model achieves a lower word error rate (WER) than both monolingual E2E models (eight of nine languages) and monolingual conventional systems (all nine languages).