 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternal Wasserstein Distance for Adversarial Attack and Defense
Paper and Code
Mar 13, 2021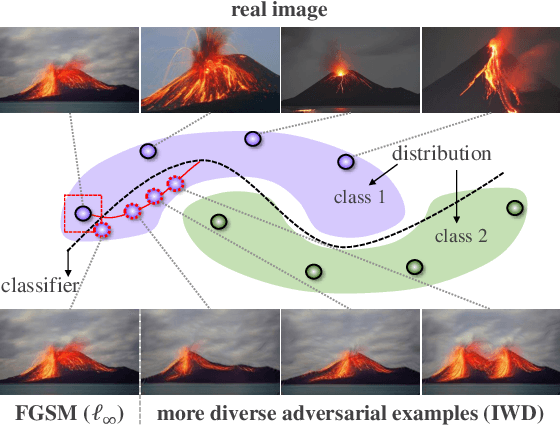
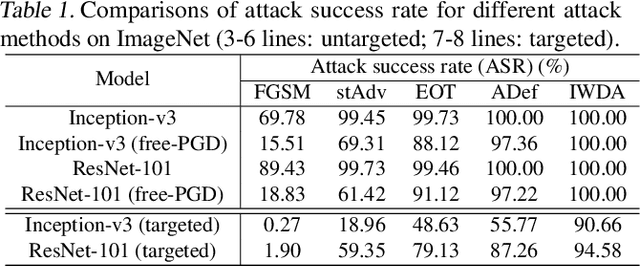
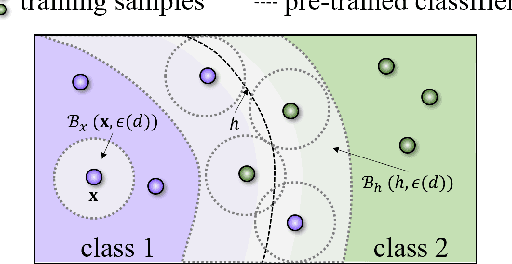
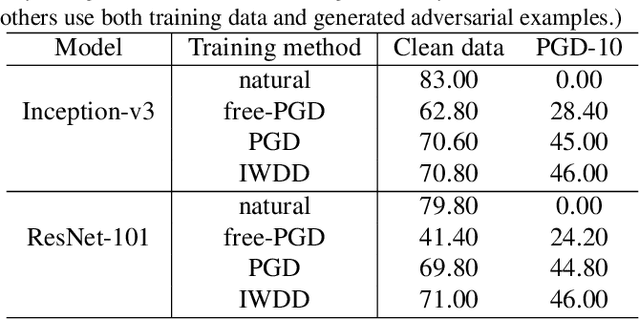
Deep neural networks (DNNs) are vulnerable to adversarial examples that can trigger misclassification of DNNs but may be imperceptible to human perception. Adversarial attack has been an important way to evaluate the robustness of DNNs. Existing attack methods on the construction of adversarial examples use such $\ell_p$ distance as a similarity metric to perturb samples. However, this kind of metric is incompatible with the underlying real-world image formation and human visual perception. In this paper, we first propose an internal Wasserstein distance (IWD) to measure image similarity between a sample and its adversarial example. We apply IWD to perform adversarial attack and defense. Specifically, we develop a novel attack method by capturing the distribution of patches in original samples. In this case, our approach is able to generate semantically similar but diverse adversarial examples that are more difficult to defend by existing defense methods. Relying on IWD, we also build a new defense method that seeks to learn robust models to defend against unseen adversarial examples. We provide both thorough theoretical and empirical evidence to support our methods.