 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing the Power of David against Goliath: Exploring Instruction Data Generation without Using Closed-Source Models
Paper and Code


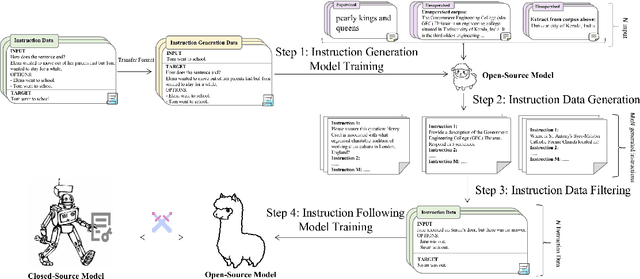

Instruction tuning is instrumental in enabling Large Language Models~(LLMs) to follow user instructions to complete various open-domain tasks. The success of instruction tuning depends on the availability of high-quality instruction data. Owing to the exorbitant cost and substandard quality of human annotation, recent works have been deeply engaged in the exploration of the utilization of powerful closed-source models to generate instruction data automatically. However, these methods carry potential risks arising from the usage requirements of powerful closed-source models, which strictly forbid the utilization of their outputs to develop machine learning models. To deal with this problem, in this work, we explore alternative approaches to generate high-quality instruction data that do not rely on closed-source models. Our exploration includes an investigation of various existing instruction generation methods, culminating in the integration of the most efficient variant with two novel strategies to enhance the quality further. Evaluation results from two benchmarks and the GPT-4 model demonstrate the effectiveness of our generated instruction data, which can outperform Alpaca, a method reliant on closed-source models. We hope that more progress can be achieved in generating high-quality instruction data without using closed-source models.