 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallusionBench: You See What You Think? Or You Think What You See? An Image-Context Reasoning Benchmark Challenging for GPT-4V, LLaVA-1.5, and Other Multi-modality Models
Paper and Code

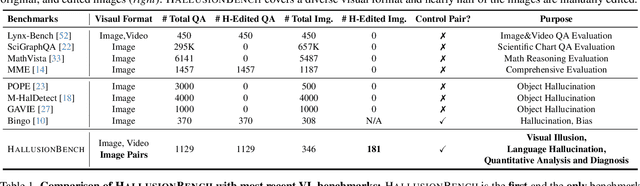

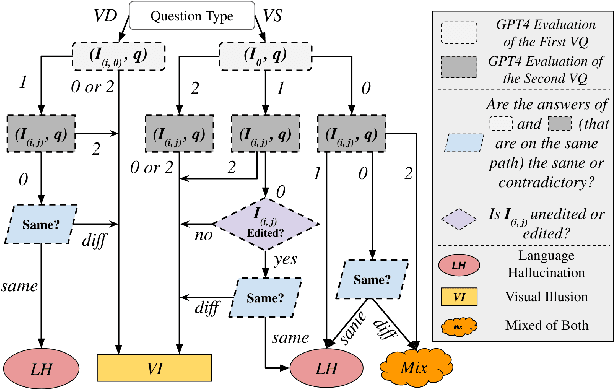
Large language models (LLMs), after being aligned with vision models and integrated into vision-language models (VLMs), can bring impressive improvement in image reasoning tasks. This was shown by the recently released GPT-4V(ison), LLaVA-1.5, etc. However, the strong language prior in these SOTA LVLMs can be a double-edged sword: they may ignore the image context and solely rely on the (even contradictory) language prior for reasoning. In contrast, the vision modules in VLMs are weaker than LLMs and may result in misleading visual representations, which are then translated to confident mistakes by LLMs. To study these two types of VLM mistakes, i.e., language hallucination and visual illusion, we curated HallusionBench, an image-context reasoning benchmark that is still challenging to even GPT-4V and LLaVA-1.5. We provide a detailed analysis of examples in HallusionBench, which sheds novel insights on the illusion or hallucination of VLMs and how to improve them in the future. The benchmark and codebase will be released at https://github.com/tianyi-lab/HallusionBench.