 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Aware Contrastive Learning for Neural Machine Translation
Paper and Code



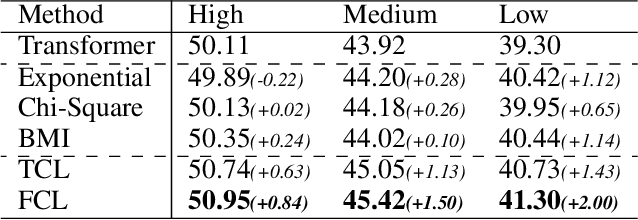
Low-frequency word prediction remains a challenge in modern neural machine translation (NMT) systems. Recent adaptive training methods promote the output of infrequent words by emphasizing their weights in the overall training objectives. Despite the improved recall of low-frequency words, their prediction precision is unexpectedly hindered by the adaptive objectives. Inspired by the observation that low-frequency words form a more compact embedding space, we tackle this challenge from a representation learning perspective. Specifically, we propose a frequency-aware token-level contrastive learning method, in which the hidden state of each decoding step is pushed away from the counterparts of other target words, in a soft contrastive way based on the corresponding word frequencies. We conduct experiments on widely used NIST Chinese-English and WMT14 English-German translation tasks. Empirical results show that our proposed methods can not only significantly improve the translation quality but also enhance lexical diversity and optimize word representation space. Further investigation reveals that, comparing with related adaptive training strategies, the superiority of our method on low-frequency word prediction lies in the robustness of token-level recall across different frequencies without sacrificing precision.