 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFPGA/DNN Co-Design: An Efficient Design Methodology for IoT Intelligence on the Edge
Paper and Code

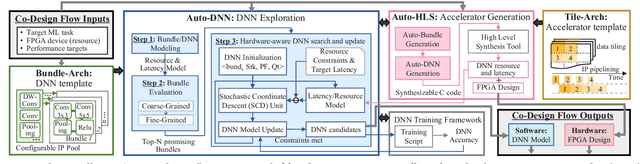


While embedded FPGAs are attractive platforms for DNN acceleration on edge-devices due to their low latency and high energy efficiency, the scarcity of resources of edge-scale FPGA devices also makes it challenging for DNN deployment. In this paper, we propose a simultaneous FPGA/DNN co-design methodology with both bottom-up and top-down approaches: a bottom-up hardware-oriented DNN model search for high accuracy, and a top-down FPGA accelerator design considering DNN-specific characteristics. We also build an automatic co-design flow, including an Auto-DNN engine to perform hardware-oriented DNN model search, as well as an Auto-HLS engine to generate synthesizable C code of the FPGA accelerator for explored DNNs. We demonstrate our co-design approach on an object detection task using PYNQ-Z1 FPGA. Results show that our proposed DNN model and accelerator outperform the state-of-the-art FPGA designs in all aspects including Intersection-over-Union (IoU) (6.2% higher), frames per second (FPS) (2.48X higher), power consumption (40% lower), and energy efficiency (2.5X higher). Compared to GPU-based solutions, our designs deliver similar accuracy but consume far less energy.