 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster CNNs with Direct Sparse Convolutions and Guided Pruning
Paper and Code
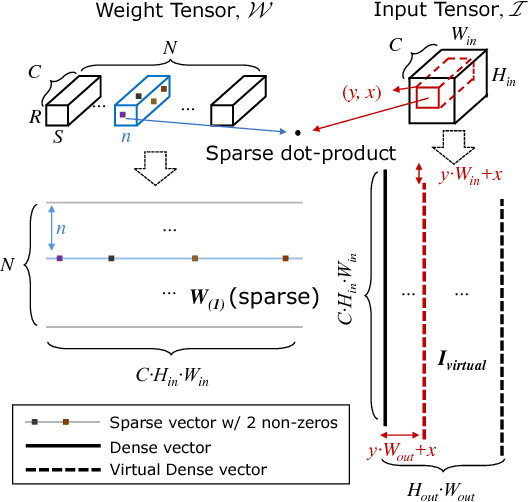

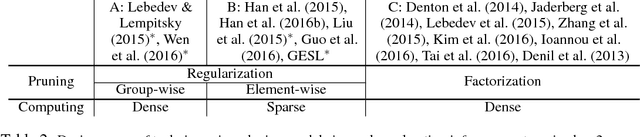
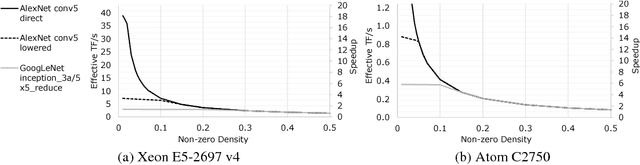
Phenomenally successful in practical inference problems, convolutional neural networks (CNN) are widely deployed in mobile devices, data centers, and even supercomputers. The number of parameters needed in CNNs, however, are often large and undesirable. Consequently, various methods have been developed to prune a CNN once it is trained. Nevertheless, the resulting CNNs offer limited benefits. While pruning the fully connected layers reduces a CNN's size considerably, it does not improve inference speed noticeably as the compute heavy parts lie in convolutions. Pruning CNNs in a way that increase inference speed often imposes specific sparsity structures, thus limiting the achievable sparsity levels. We present a method to realize simultaneously size economy and speed improvement while pruning CNNs. Paramount to our success is an efficient general sparse-with-dense matrix multiplication implementation that is applicable to convolution of feature maps with kernels of arbitrary sparsity patterns. Complementing this, we developed a performance model that predicts sweet spots of sparsity levels for different layers and on different computer architectures. Together, these two allow us to demonstrate 3.1--7.3$\times$ convolution speedups over dense convolution in AlexNet, on Intel Atom, Xeon, and Xeon Phi processors, spanning the spectrum from mobile devices to supercomputers. We also open source our project at https://github.com/IntelLabs/SkimCaffe.