 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Abstraction in Visual Model-Based Reinforcement Learning
Paper and Code
Dec 04, 2019
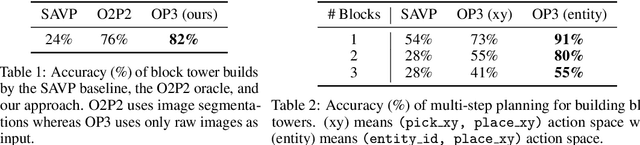


This paper tests the hypothesis that modeling a scene in terms of entities and their local interactions, as opposed to modeling the scene globally, provides a significant benefit in generalizing to physical tasks in a combinatorial space the learner has not encountered before. We present object-centric perception, prediction, and planning (OP3), which to the best of our knowledge is the first entity-centric dynamic latent variable framework for model-based reinforcement learning that acquires entity representations from raw visual observations without supervision and uses them to predict and plan. OP3 enforces entity-abstraction -- symmetric processing of each entity representation with the same locally-scoped function -- which enables it to scale to model different numbers and configurations of objects from those in training. Our approach to solving the key technical challenge of grounding these entity representations to actual objects in the environment is to frame this variable binding problem as an inference problem, and we developing an interactive inference algorithm that uses temporal continuity and interactive feedback to bind information about object properties to the entity variables. On block-stacking tasks, OP3 generalizes to novel block configurations and more objects than observed during training, outperforming an oracle model that assumes access to object supervision and achieving two to three times better accuracy than a state-of-the-art video prediction model.