 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Speaker-Attributed ASR with Transformer
Paper and Code
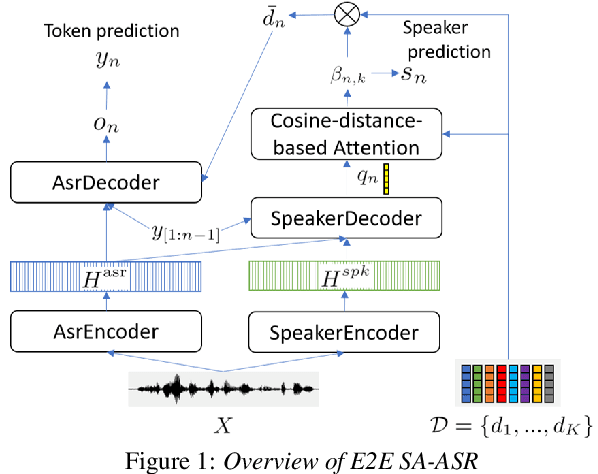
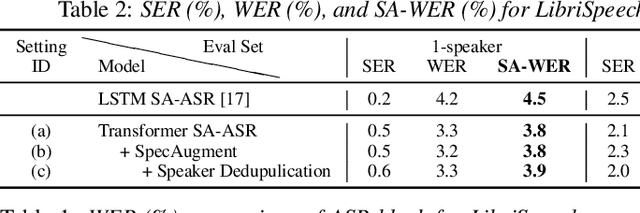
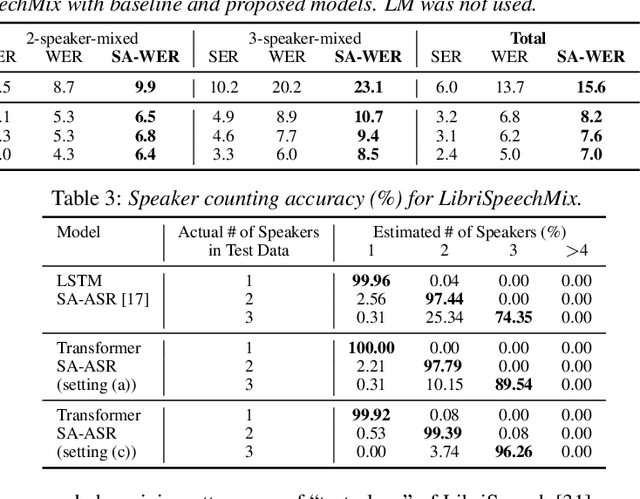
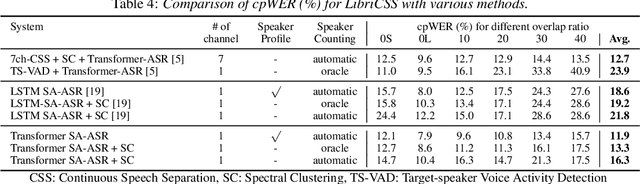
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.