 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElucidating the Design Space of Multimodal Protein Language Models
Paper and Code
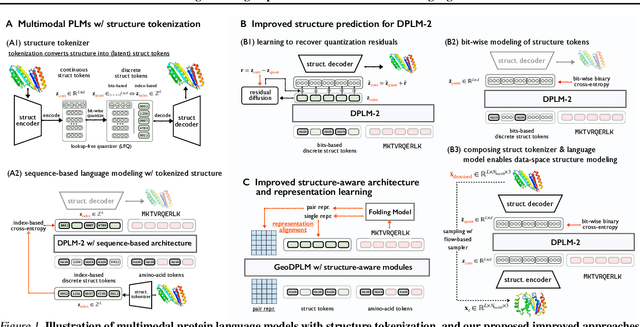
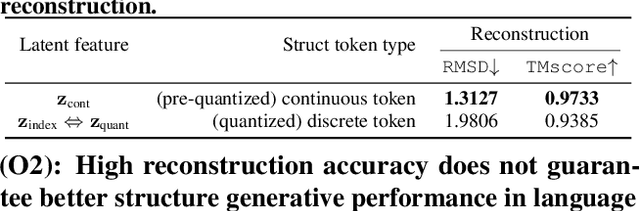
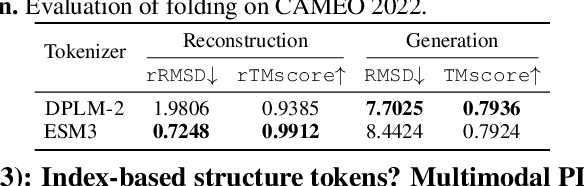
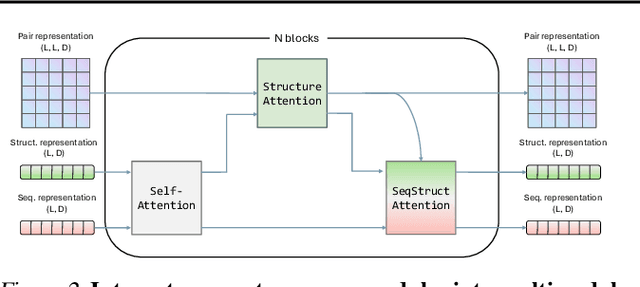
Multimodal protein language models (PLMs) integrate sequence and token-based structural information, serving as a powerful foundation for protein modeling, generation, and design. However, the reliance on tokenizing 3D structures into discrete tokens causes substantial loss of fidelity about fine-grained structural details and correlations. In this paper, we systematically elucidate the design space of multimodal PLMs to overcome their limitations. We identify tokenization loss and inaccurate structure token predictions by the PLMs as major bottlenecks. To address these, our proposed design space covers improved generative modeling, structure-aware architectures and representation learning, and data exploration. Our advancements approach finer-grained supervision, demonstrating that token-based multimodal PLMs can achieve robust structural modeling. The effective design methods dramatically improve the structure generation diversity, and notably, folding abilities of our 650M model by reducing the RMSD from 5.52 to 2.36 on PDB testset, even outperforming 3B baselines and on par with the specialized folding models.