 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Fusion for Goal Directed Robotic Vision
Paper and Code
Nov 21, 2018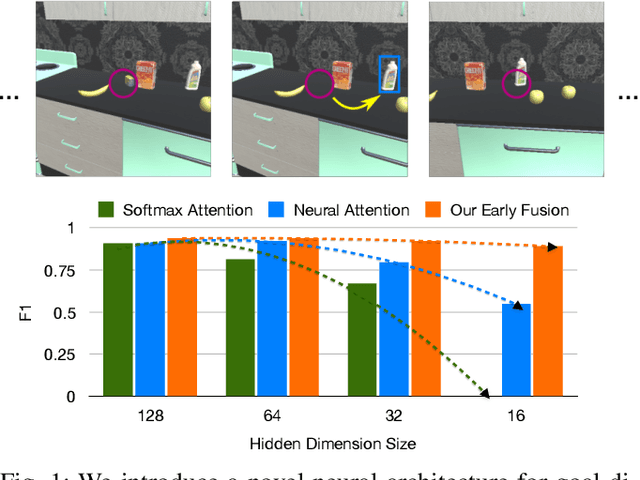

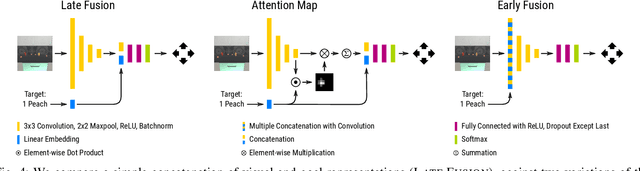
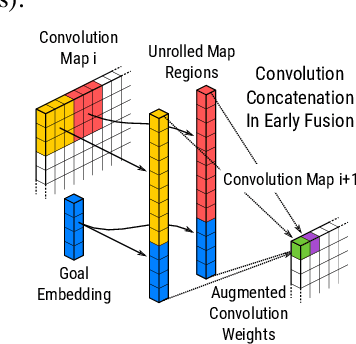
Increasingly, perceptual systems are being codified as strict pipelines wherein vision is treated as a pre-processing step to provide a dense representation of the scene to planners for high level reasoning downstream. Problematically, this paradigm forces models to represent nearly every aspect of the scene even if it has no bearing on the task at hand. In this work, we flip this paradigm, by introducing vision models whose feature representations are conditioned on embedded representations of the agent's goal. This allows the model to build scene descriptions that are specifically designed to help achieve that goal. We find this leads to models that learn faster, are substantially more parameter efficient and more robust than existing attention mechanisms in our domain. Our experiments are performed on a simulated robot item retrieval problem and trained in a fully end-to-end manner via imitation learning.