 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDFIL: Deepfake Incremental Learning by Exploiting Domain-invariant Forgery Clues
Paper and Code
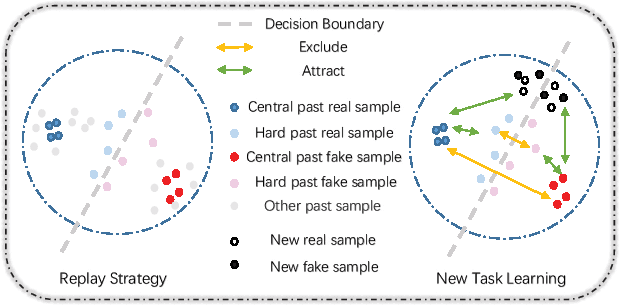

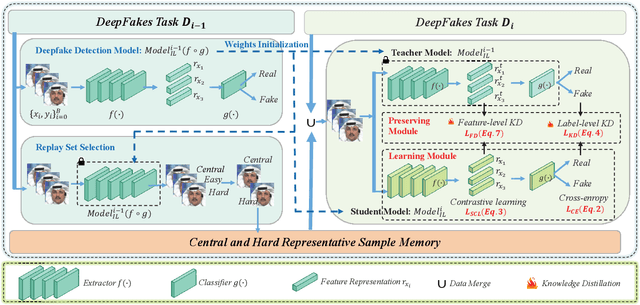

The malicious use and widespread dissemination of deepfake pose a significant crisis of trust. Current deepfake detection models can generally recognize forgery images by training on a large dataset. However, the accuracy of detection models degrades significantly on images generated by new deepfake methods due to the difference in data distribution. To tackle this issue, we present a novel incremental learning framework that improves the generalization of deepfake detection models by continual learning from a small number of new samples. To cope with different data distributions, we propose to learn a domain-invariant representation based on supervised contrastive learning, preventing overfit to the insufficient new data. To mitigate catastrophic forgetting, we regularize our model in both feature-level and label-level based on a multi-perspective knowledge distillation approach. Finally, we propose to select both central and hard representative samples to update the replay set, which is beneficial for both domain-invariant representation learning and rehearsal-based knowledge preserving. We conduct extensive experiments on four benchmark datasets, obtaining the new state-of-the-art average forgetting rate of 7.01 and average accuracy of 85.49 on FF++, DFDC-P, DFD, and CDF2. Our code is released at https://github.com/DeepFakeIL/DFIL.