 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep processing of structured data
Paper and Code
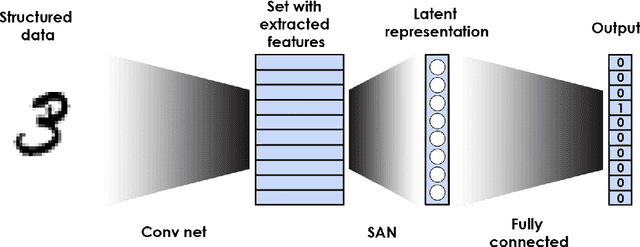
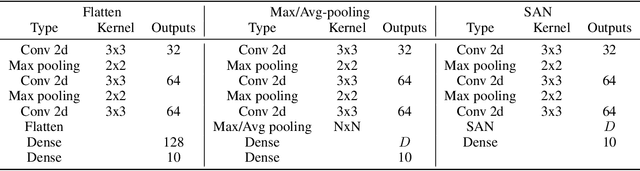
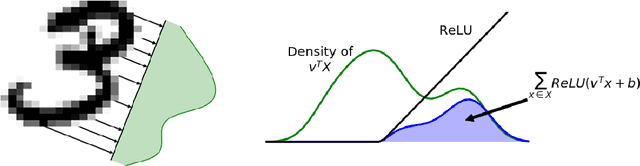
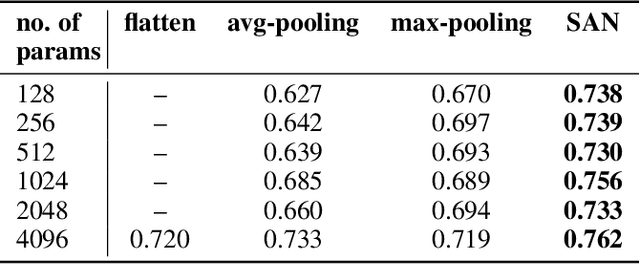
We construct a general unified framework for learning representation of structured data, i.e. data which cannot be represented as the fixed-length vectors (e.g. sets, graphs, texts or images of varying sizes). The key factor is played by an intermediate network called SAN (Set Aggregating Network), which maps a structured object to a fixed length vector in a high dimensional latent space. Our main theoretical result shows that for sufficiently large dimension of the latent space, SAN is capable of learning a unique representation for every input example. Experiments demonstrate that replacing pooling operation by SAN in convolutional networks leads to better results in classifying images with different sizes. Moreover, its direct application to text and graph data allows to obtain results close to SOTA, by simpler networks with smaller number of parameters than competitive models.