 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning from Noisy Image Labels with Quality Embedding
Paper and Code

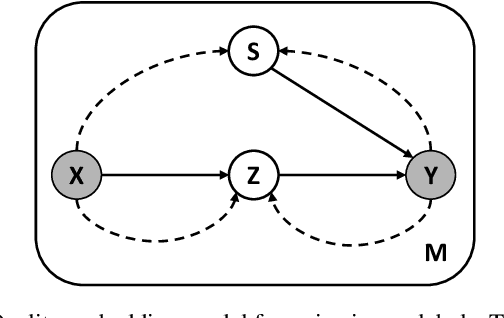
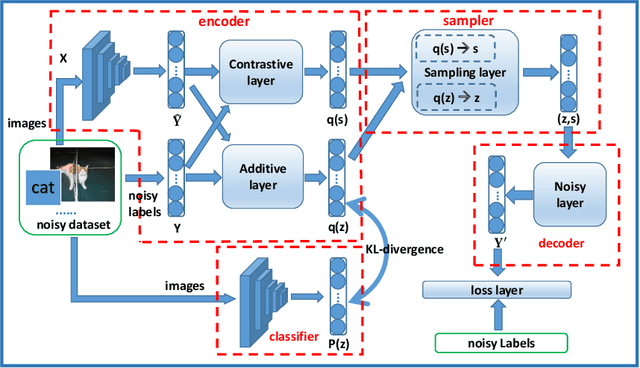
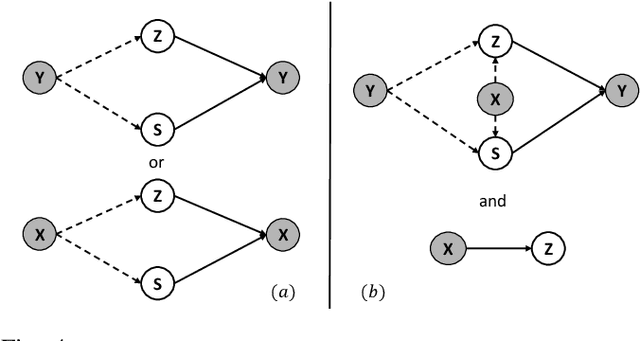
There is an emerging trend to leverage noisy image datasets in many visual recognition tasks. However, the label noise among the datasets severely degenerates the \mbox{performance of deep} learning approaches. Recently, one mainstream is to introduce the latent label to handle label noise, which has shown promising improvement in the network designs. Nevertheless, the mismatch between latent labels and noisy labels still affects the predictions in such methods. To address this issue, we propose a quality embedding model, which explicitly introduces a quality variable to represent the trustworthiness of noisy labels. Our key idea is to identify the mismatch between the latent and noisy labels by embedding the quality variables into different subspaces, which effectively minimizes the noise effect. At the same time, the high-quality labels is still able to be applied for training. To instantiate the model, we further propose a Contrastive-Additive Noise network (CAN), which consists of two important layers: (1) the contrastive layer estimates the quality variable in the embedding space to reduce noise effect; and (2) the additive layer aggregates the prior predictions and noisy labels as the posterior to train the classifier. Moreover, to tackle the optimization difficulty, we deduce an SGD algorithm with the reparameterization tricks, which makes our method scalable to big data. We conduct the experimental evaluation of the proposed method over a range of noisy image datasets. Comprehensive results have demonstrated CAN outperforms the state-of-the-art deep learning approaches.