 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossover-Net: Leveraging the Vertical-Horizontal Crossover Relation for Robust Segmentation
Paper and Code
Apr 03, 2020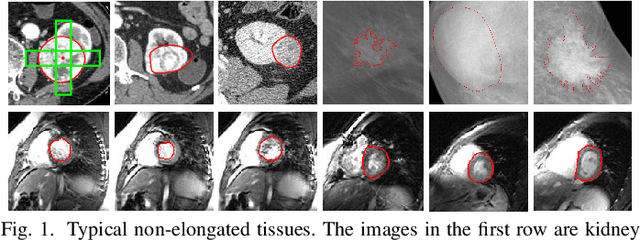
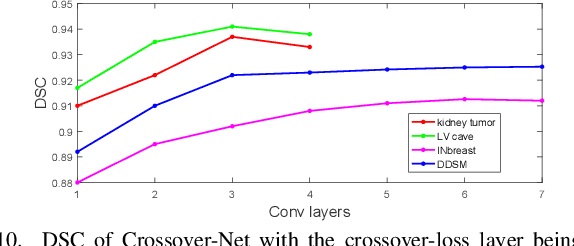
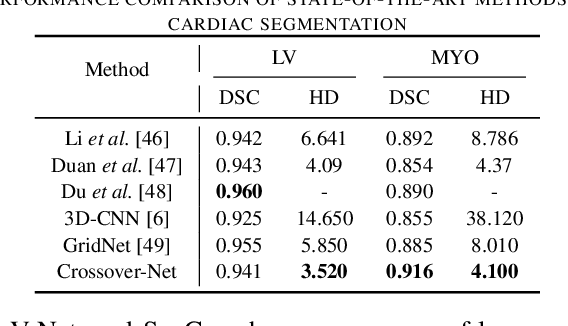
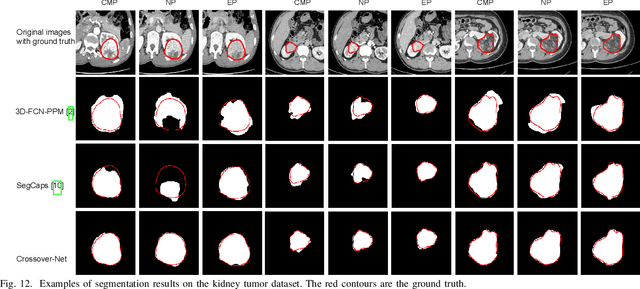
Robust segmentation for non-elongated tissues in medical images is hard to realize due to the large variation of the shape, size, and appearance of these tissues in different patients. In this paper, we present an end-to-end trainable deep segmentation model termed Crossover-Net for robust segmentation in medical images. Our proposed model is inspired by an insightful observation: during segmentation, the representation from the horizontal and vertical directions can provide different local appearance and orthogonality context information, which helps enhance the discrimination between different tissues by simultaneously learning from these two directions. Specifically, by converting the segmentation task to a pixel/voxel-wise prediction problem, firstly, we originally propose a cross-shaped patch, namely crossover-patch, which consists of a pair of (orthogonal and overlapped) vertical and horizontal patches, to capture the orthogonal vertical and horizontal relation. Then, we develop the Crossover-Net to learn the vertical-horizontal crossover relation captured by our crossover-patches. To achieve this goal, for learning the representation on a typical crossover-patch, we design a novel loss function to (1) impose the consistency on the overlap region of the vertical and horizontal patches and (2) preserve the diversity on their non-overlap regions. We have extensively evaluated our method on CT kidney tumor, MR cardiac, and X-ray breast mass segmentation tasks. Promising results are achieved according to our extensive evaluation and comparison with the state-of-the-art segmentation models.