 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConv-Adapter: Exploring Parameter Efficient Transfer Learning for ConvNets
Paper and Code


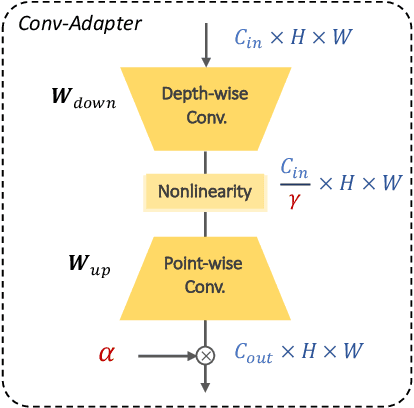

While parameter efficient tuning (PET) methods have shown great potential with transformer architecture on Natural Language Processing (NLP) tasks, their effectiveness is still under-studied with large-scale ConvNets on Computer Vision (CV) tasks. This paper proposes Conv-Adapter, a PET module designed for ConvNets. Conv-Adapter is light-weight, domain-transferable, and architecture-agnostic with generalized performance on different tasks. When transferring on downstream tasks, Conv-Adapter learns tasks-specific feature modulation to the intermediate representations of backbone while keeping the pre-trained parameters frozen. By introducing only a tiny amount of learnable parameters, e.g., only 3.5% full fine-tuning parameters of ResNet50, Conv-Adapter outperforms previous PET baseline methods and achieves comparable or surpasses the performance of full fine-tuning on 23 classification tasks of various domains. It also presents superior performance on few-shot classifications, with an average margin of 3.39%. Beyond classification, Conv-Adapter can generalize to detection and segmentation tasks with more than 50% reduction of parameters but comparable performance to the traditional full fine-tuning.