 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Self-supervised Learning: Towards Universal Multi-modal Medical Data Representation Learning
Paper and Code
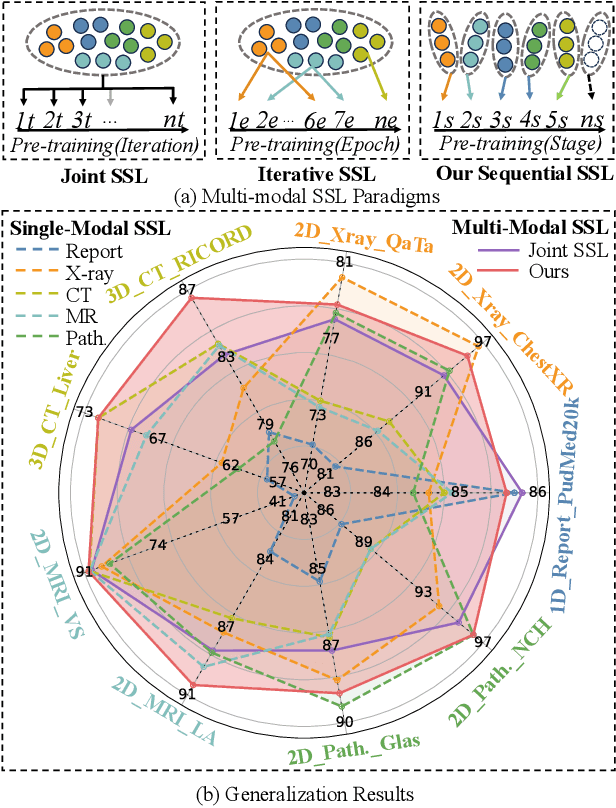
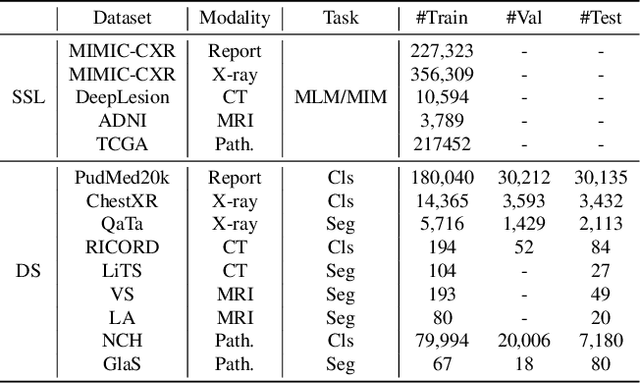
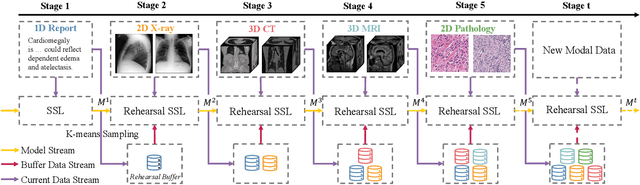
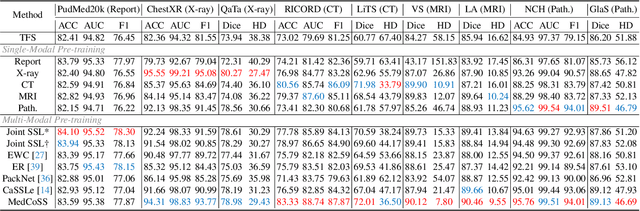
Self-supervised learning is an efficient pre-training method for medical image analysis. However, current research is mostly confined to specific-modality data pre-training, consuming considerable time and resources without achieving universality across different modalities. A straightforward solution is combining all modality data for joint self-supervised pre-training, which poses practical challenges. Firstly, our experiments reveal conflicts in representation learning as the number of modalities increases. Secondly, multi-modal data collected in advance cannot cover all real-world scenarios. In this paper, we reconsider versatile self-supervised learning from the perspective of continual learning and propose MedCoSS, a continuous self-supervised learning approach for multi-modal medical data. Unlike joint self-supervised learning, MedCoSS assigns different modality data to different training stages, forming a multi-stage pre-training process. To balance modal conflicts and prevent catastrophic forgetting, we propose a rehearsal-based continual learning method. We introduce the k-means sampling strategy to retain data from previous modalities and rehearse it when learning new modalities. Instead of executing the pretext task on buffer data, a feature distillation strategy and an intra-modal mixup strategy are applied to these data for knowledge retention. We conduct continuous self-supervised pre-training on a large-scale multi-modal unlabeled dataset, including clinical reports, X-rays, CT scans, MRI scans, and pathological images. Experimental results demonstrate MedCoSS's exceptional generalization ability across nine downstream datasets and its significant scalability in integrating new modality data. Code and pre-trained weight are available at https://github.com/yeerwen/MedCoSS.