 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Adapter: Better Vision-Language Models with Feature Adapters
Paper and Code
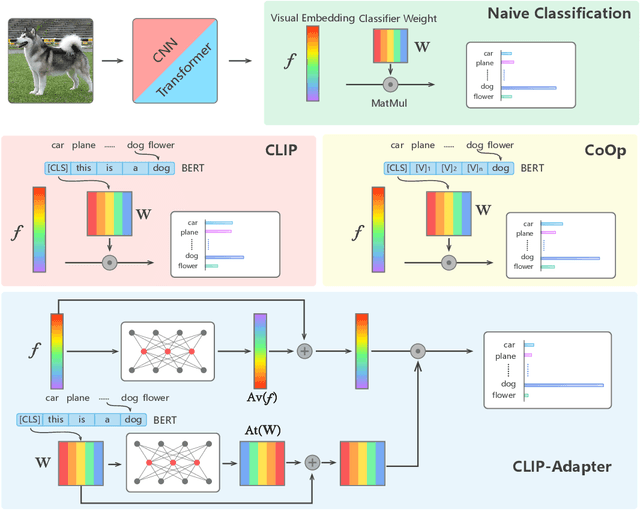
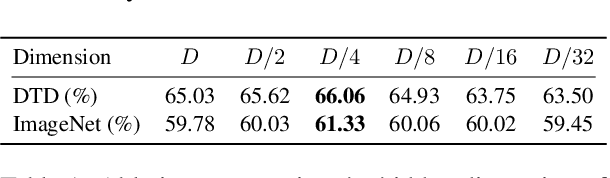
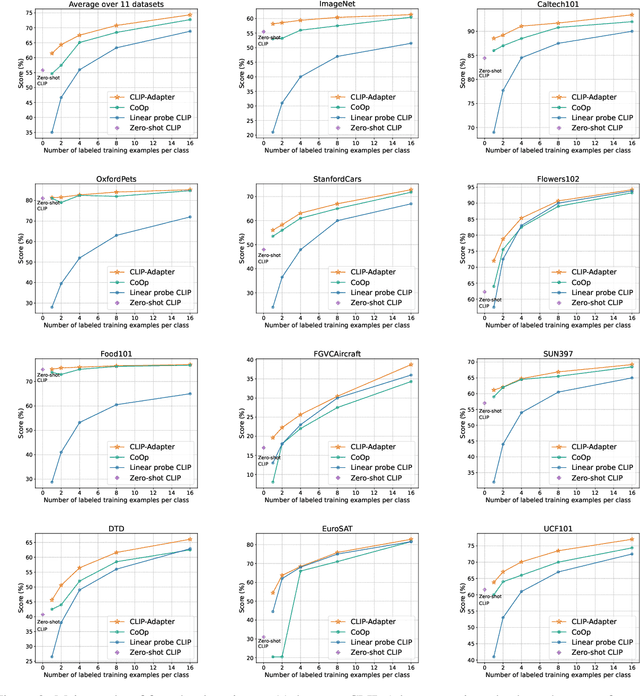
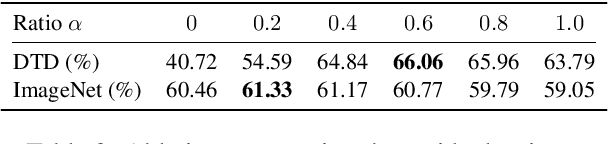
Large-scale contrastive vision-language pre-training has shown significant progress in visual representation learning. Unlike traditional visual systems trained by a fixed set of discrete labels, a new paradigm was introduced in \cite{radford2021learning} to directly learn to align images with raw texts in an open-vocabulary setting. On downstream tasks, a carefully chosen text prompt is employed to make zero-shot predictions.~To avoid non-trivial prompt engineering, context optimization \cite{zhou2021coop} has been proposed to learn continuous vectors as task-specific prompts with few-shot training examples.~In this paper, we show that there is an alternative path to achieve better vision-language models other than prompt tuning.~While prompt tuning is for the textual inputs, we propose CLIP-Adapter to conduct fine-tuning with feature adapters on either visual or language branch. Specifically, CLIP-Adapter adopts an additional bottleneck layer to learn new features and performs residual-style feature blending with the original pre-trained features.~As a consequence, CLIP-Adapter is able to outperform context optimization while maintains a simple design. Experiments and extensive ablation studies on various visual classification tasks demonstrate the effectiveness of our approach.