 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChordal Sparsity for Lipschitz Constant Estimation of Deep Neural Networks
Paper and Code
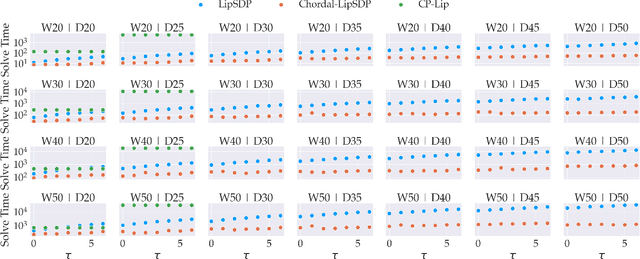
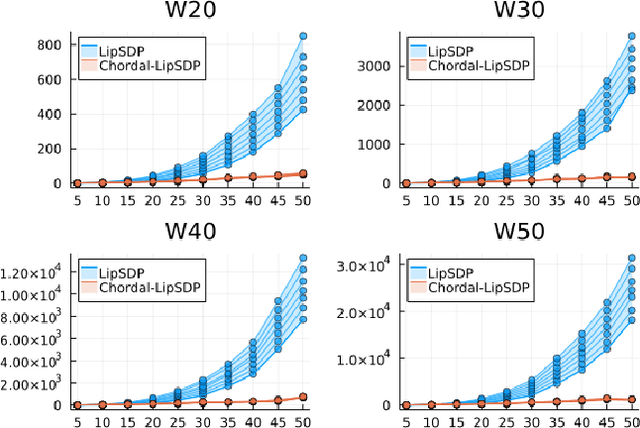
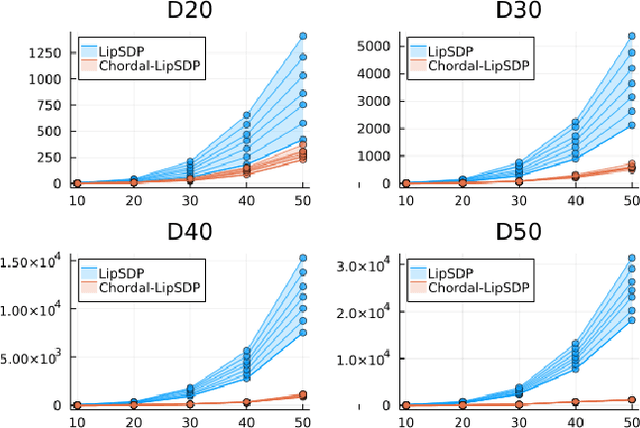
Lipschitz constants of neural networks allow for guarantees of robustness in image classification, safety in controller design, and generalizability beyond the training data. As calculating Lipschitz constants is NP-hard, techniques for estimating Lipschitz constants must navigate the trade-off between scalability and accuracy. In this work, we significantly push the scalability frontier of a semidefinite programming technique known as LipSDP while achieving zero accuracy loss. We first show that LipSDP has chordal sparsity, which allows us to derive a chordally sparse formulation that we call Chordal-LipSDP. The key benefit is that the main computational bottleneck of LipSDP, a large semidefinite constraint, is now decomposed into an equivalent collection of smaller ones: allowing Chordal-LipSDP to outperform LipSDP particularly as the network depth grows. Moreover, our formulation uses a tunable sparsity parameter that enables one to gain tighter estimates without incurring a significant computational cost. We illustrate the scalability of our approach through extensive numerical experiments.