 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCDChat: A Large Multimodal Model for Remote Sensing Change Description
Paper and Code
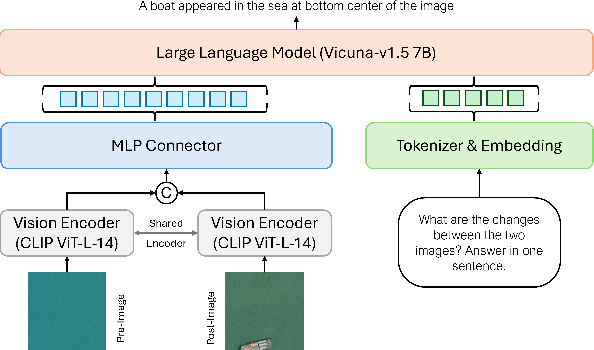
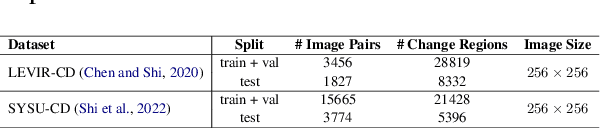
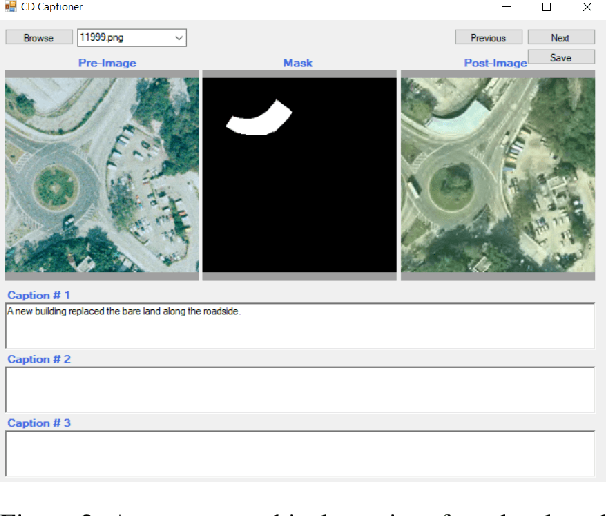
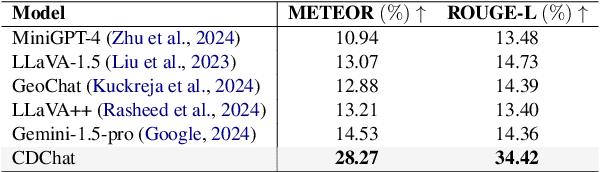
Large multimodal models (LMMs) have shown encouraging performance in the natural image domain using visual instruction tuning. However, these LMMs struggle to describe the content of remote sensing images for tasks such as image or region grounding, classification, etc. Recently, GeoChat make an effort to describe the contents of the RS images. Although, GeoChat achieves promising performance for various RS tasks, it struggles to describe the changes between bi-temporal RS images which is a key RS task. This necessitates the development of an LMM that can describe the changes between the bi-temporal RS images. However, there is insufficiency of datasets that can be utilized to tune LMMs. In order to achieve this, we introduce a change description instruction dataset that can be utilized to finetune an LMM and provide better change descriptions for RS images. Furthermore, we show that the LLaVA-1.5 model, with slight modifications, can be finetuned on the change description instruction dataset and achieve favorably better performance.