 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCACER: Clinical Concept Annotations for Cancer Events and Relations
Paper and Code
Sep 05, 2024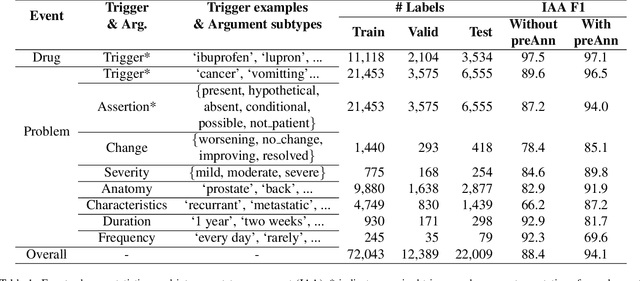
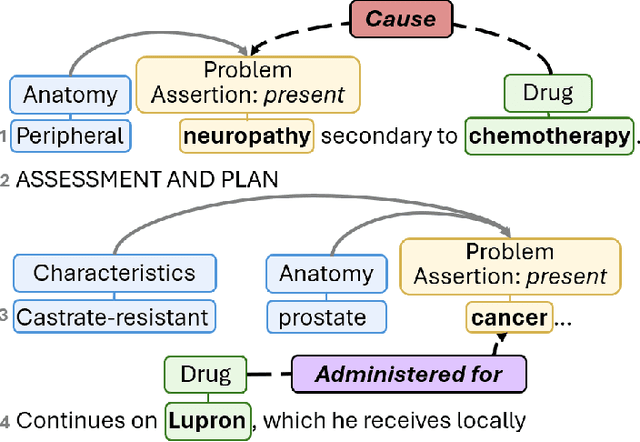
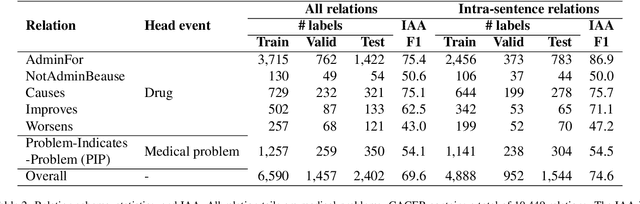
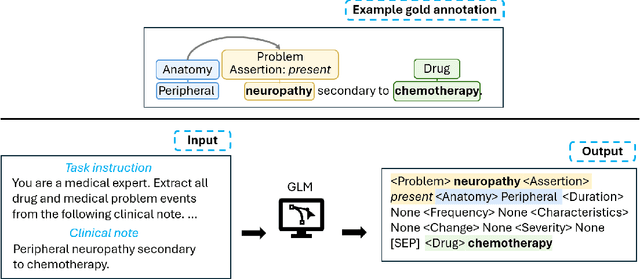
Clinical notes contain unstructured representations of patient histories, including the relationships between medical problems and prescription drugs. To investigate the relationship between cancer drugs and their associated symptom burden, we extract structured, semantic representations of medical problem and drug information from the clinical narratives of oncology notes. We present Clinical Concept Annotations for Cancer Events and Relations (CACER), a novel corpus with fine-grained annotations for over 48,000 medical problems and drug events and 10,000 drug-problem and problem-problem relations. Leveraging CACER, we develop and evaluate transformer-based information extraction (IE) models such as BERT, Flan-T5, Llama3, and GPT-4 using fine-tuning and in-context learning (ICL). In event extraction, the fine-tuned BERT and Llama3 models achieved the highest performance at 88.2-88.0 F1, which is comparable to the inter-annotator agreement (IAA) of 88.4 F1. In relation extraction, the fine-tuned BERT, Flan-T5, and Llama3 achieved the highest performance at 61.8-65.3 F1. GPT-4 with ICL achieved the worst performance across both tasks. The fine-tuned models significantly outperformed GPT-4 in ICL, highlighting the importance of annotated training data and model optimization. Furthermore, the BERT models performed similarly to Llama3. For our task, LLMs offer no performance advantage over the smaller BERT models. The results emphasize the need for annotated training data to optimize models. Multiple fine-tuned transformer models achieved performance comparable to IAA for several extraction tasks.