 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Active Learning via Improving Test Performance
Paper and Code
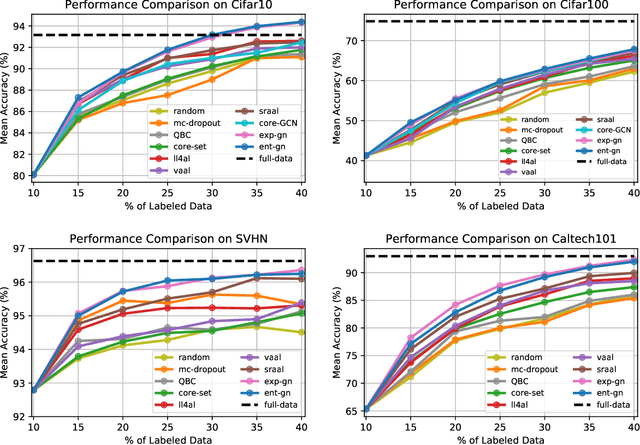

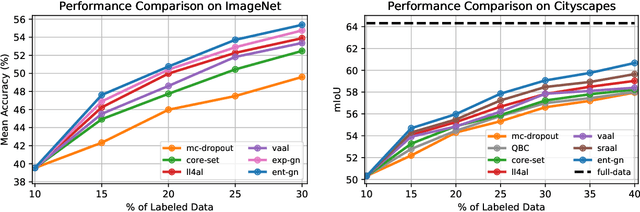
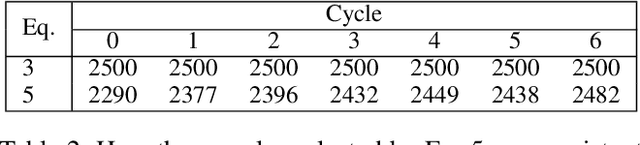
Central to active learning (AL) is what data should be selected for annotation. Existing works attempt to select highly uncertain or informative data for annotation. Nevertheless, it remains unclear how selected data impacts the test performance of the task model used in AL. In this work, we explore such an impact by theoretically proving that selecting unlabeled data of higher gradient norm leads to a lower upper bound of test loss, resulting in a better test performance. However, due to the lack of label information, directly computing gradient norm for unlabeled data is infeasible. To address this challenge, we propose two schemes, namely expected-gradnorm and entropy-gradnorm. The former computes the gradient norm by constructing an expected empirical loss while the latter constructs an unsupervised loss with entropy. Furthermore, we integrate the two schemes in a universal AL framework. We evaluate our method on classical image classification and semantic segmentation tasks. To demonstrate its competency in domain applications and its robustness to noise, we also validate our method on a cellular imaging analysis task, namely cryo-Electron Tomography subtomogram classification. Results demonstrate that our method achieves superior performance against the state-of-the-art. Our source code is available at https://github.com/xulabs/aitom