 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAll-neural beamformer for continuous speech separation
Paper and Code
Oct 13, 2021
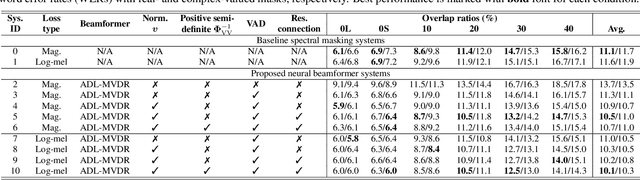


Continuous speech separation (CSS) aims to separate overlapping voices from a continuous influx of conversational audio containing an unknown number of utterances spoken by an unknown number of speakers. A common application scenario is transcribing a meeting conversation recorded by a microphone array. Prior studies explored various deep learning models for time-frequency mask estimation, followed by a minimum variance distortionless response (MVDR) filter to improve the automatic speech recognition (ASR) accuracy. The performance of these methods is fundamentally upper-bounded by MVDR's spatial selectivity. Recently, the all deep learning MVDR (ADL-MVDR) model was proposed for neural beamforming and demonstrated superior performance in a target speech extraction task using pre-segmented input. In this paper, we further adapt ADL-MVDR to the CSS task with several enhancements to enable end-to-end neural beamforming. The proposed system achieves significant word error rate reduction over a baseline spectral masking system on the LibriCSS dataset. Moreover, the proposed neural beamformer is shown to be comparable to a state-of-the-art MVDR-based system in real meeting transcription tasks, including AMI, while showing potentials to further simplify the runtime implementation and reduce the system latency with frame-wise processing.