 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3rd Place Solution for MOSE Track in CVPR 2024 PVUW workshop: Complex Video Object Segmentation
Paper and Code
Jun 06, 2024


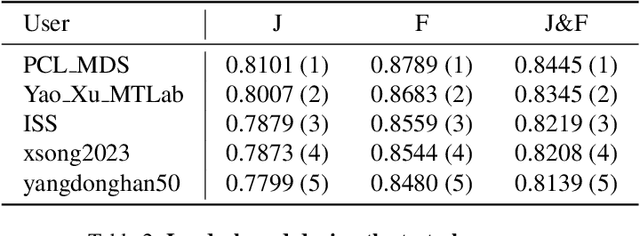
Video Object Segmentation (VOS) is a vital task in computer vision, focusing on distinguishing foreground objects from the background across video frames. Our work draws inspiration from the Cutie model, and we investigate the effects of object memory, the total number of memory frames, and input resolution on segmentation performance. This report validates the effectiveness of our inference method on the coMplex video Object SEgmentation (MOSE) dataset, which features complex occlusions. Our experimental results demonstrate that our approach achieves a J\&F score of 0.8139 on the test set, securing the third position in the final ranking. These findings highlight the robustness and accuracy of our method in handling challenging VOS scenarios.