 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometric Transformation Uncertainty for Improving 3D Fetal Brain Pose Prediction from Freehand 2D Ultrasound Videos
May 21, 2024Accurately localizing two-dimensional (2D) ultrasound (US) fetal brain images in the 3D brain, using minimal computational resources, is an important task for automated US analysis of fetal growth and development. We propose an uncertainty-aware deep learning model for automated 3D plane localization in 2D fetal brain images. Specifically, a multi-head network is trained to jointly regress 3D plane pose from 2D images in terms of different geometric transformations. The model explicitly learns to predict uncertainty to allocate higher weight to inputs with low variances across different transformations to improve performance. Our proposed method, QAERTS, demonstrates superior pose estimation accuracy than the state-of-the-art and most of the uncertainty-based approaches, leading to 9% improvement on plane angle (PA) for localization accuracy, and 8% on normalized cross-correlation (NCC) for sampled image quality. QAERTS also demonstrates efficiency, containing 5$\times$ fewer parameters than ensemble-based approach, making it advantageous in resource-constrained settings. In addition, QAERTS proves to be more robust to noise effects observed in freehand US scanning by leveraging rotational discontinuities and explicit output uncertainties.
ImplicitVol: Sensorless 3D Ultrasound Reconstruction with Deep Implicit Representation
Sep 24, 2021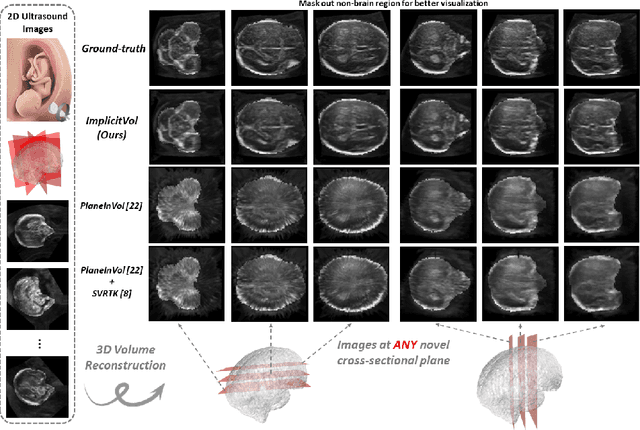

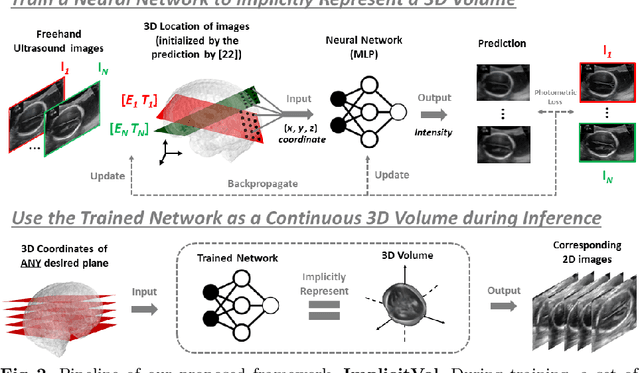
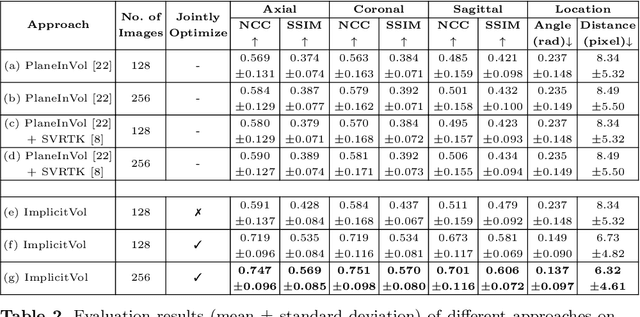
The objective of this work is to achieve sensorless reconstruction of a 3D volume from a set of 2D freehand ultrasound images with deep implicit representation. In contrast to the conventional way that represents a 3D volume as a discrete voxel grid, we do so by parameterizing it as the zero level-set of a continuous function, i.e. implicitly representing the 3D volume as a mapping from the spatial coordinates to the corresponding intensity values. Our proposed model, termed as ImplicitVol, takes a set of 2D scans and their estimated locations in 3D as input, jointly re?fing the estimated 3D locations and learning a full reconstruction of the 3D volume. When testing on real 2D ultrasound images, novel cross-sectional views that are sampled from ImplicitVol show significantly better visual quality than those sampled from existing reconstruction approaches, outperforming them by over 30% (NCC and SSIM), between the output and ground-truth on the 3D volume testing data. The code will be made publicly available.