 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVivid-VR: Distilling Concepts from Text-to-Video Diffusion Transformer for Photorealistic Video Restoration
Aug 20, 2025



We present Vivid-VR, a DiT-based generative video restoration method built upon an advanced T2V foundation model, where ControlNet is leveraged to control the generation process, ensuring content consistency. However, conventional fine-tuning of such controllable pipelines frequently suffers from distribution drift due to limitations in imperfect multimodal alignment, resulting in compromised texture realism and temporal coherence. To tackle this challenge, we propose a concept distillation training strategy that utilizes the pretrained T2V model to synthesize training samples with embedded textual concepts, thereby distilling its conceptual understanding to preserve texture and temporal quality. To enhance generation controllability, we redesign the control architecture with two key components: 1) a control feature projector that filters degradation artifacts from input video latents to minimize their propagation through the generation pipeline, and 2) a new ControlNet connector employing a dual-branch design. This connector synergistically combines MLP-based feature mapping with cross-attention mechanism for dynamic control feature retrieval, enabling both content preservation and adaptive control signal modulation. Extensive experiments show that Vivid-VR performs favorably against existing approaches on both synthetic and real-world benchmarks, as well as AIGC videos, achieving impressive texture realism, visual vividness, and temporal consistency. The codes and checkpoints are publicly available at https://github.com/csbhr/Vivid-VR.
Accelerating Learned Video Compression via Low-Resolution Representation Learning
Jul 23, 2024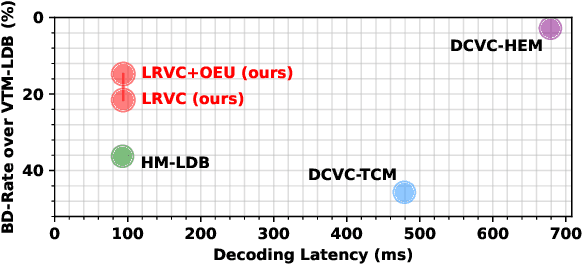

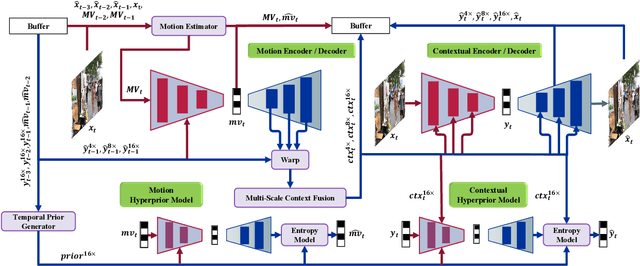

In recent years, the field of learned video compression has witnessed rapid advancement, exemplified by the latest neural video codecs DCVC-DC that has outperformed the upcoming next-generation codec ECM in terms of compression ratio. Despite this, learned video compression frameworks often exhibit low encoding and decoding speeds primarily due to their increased computational complexity and unnecessary high-resolution spatial operations, which hugely hinder their applications in reality. In this work, we introduce an efficiency-optimized framework for learned video compression that focuses on low-resolution representation learning, aiming to significantly enhance the encoding and decoding speeds. Firstly, we diminish the computational load by reducing the resolution of inter-frame propagated features obtained from reused features of decoded frames, including I-frames. We implement a joint training strategy for both the I-frame and P-frame models, further improving the compression ratio. Secondly, our approach efficiently leverages multi-frame priors for parameter prediction, minimizing computation at the decoding end. Thirdly, we revisit the application of the Online Encoder Update (OEU) strategy for high-resolution sequences, achieving notable improvements in compression ratio without compromising decoding efficiency. Our efficiency-optimized framework has significantly improved the balance between compression ratio and speed for learned video compression. In comparison to traditional codecs, our method achieves performance levels on par with the low-decay P configuration of the H.266 reference software VTM. Furthermore, when contrasted with DCVC-HEM, our approach delivers a comparable compression ratio while boosting encoding and decoding speeds by a factor of 3 and 7, respectively. On RTX 2080Ti, our method can decode each 1080p frame under 100ms.
Latent Modulated Function for Computational Optimal Continuous Image Representation
Apr 25, 2024



The recent work Local Implicit Image Function (LIIF) and subsequent Implicit Neural Representation (INR) based works have achieved remarkable success in Arbitrary-Scale Super-Resolution (ASSR) by using MLP to decode Low-Resolution (LR) features. However, these continuous image representations typically implement decoding in High-Resolution (HR) High-Dimensional (HD) space, leading to a quadratic increase in computational cost and seriously hindering the practical applications of ASSR. To tackle this problem, we propose a novel Latent Modulated Function (LMF), which decouples the HR-HD decoding process into shared latent decoding in LR-HD space and independent rendering in HR Low-Dimensional (LD) space, thereby realizing the first computational optimal paradigm of continuous image representation. Specifically, LMF utilizes an HD MLP in latent space to generate latent modulations of each LR feature vector. This enables a modulated LD MLP in render space to quickly adapt to any input feature vector and perform rendering at arbitrary resolution. Furthermore, we leverage the positive correlation between modulation intensity and input image complexity to design a Controllable Multi-Scale Rendering (CMSR) algorithm, offering the flexibility to adjust the decoding efficiency based on the rendering precision. Extensive experiments demonstrate that converting existing INR-based ASSR methods to LMF can reduce the computational cost by up to 99.9%, accelerate inference by up to 57 times, and save up to 76% of parameters, while maintaining competitive performance. The code is available at https://github.com/HeZongyao/LMF.
Dynamic Implicit Image Function for Efficient Arbitrary-Scale Image Representation
Jun 21, 2023Recent years have witnessed the remarkable success of implicit neural representation methods. The recent work Local Implicit Image Function (LIIF) has achieved satisfactory performance for continuous image representation, where pixel values are inferred from a neural network in a continuous spatial domain. However, the computational cost of such implicit arbitrary-scale super-resolution (SR) methods increases rapidly as the scale factor increases, which makes arbitrary-scale SR time-consuming. In this paper, we propose Dynamic Implicit Image Function (DIIF), which is a fast and efficient method to represent images with arbitrary resolution. Instead of taking an image coordinate and the nearest 2D deep features as inputs to predict its pixel value, we propose a coordinate grouping and slicing strategy, which enables the neural network to perform decoding from coordinate slices to pixel value slices. We further propose a Coarse-to-Fine Multilayer Perceptron (C2F-MLP) to perform decoding with dynamic coordinate slicing, where the number of coordinates in each slice varies as the scale factor varies. With dynamic coordinate slicing, DIIF significantly reduces the computational cost when encountering arbitrary-scale SR. Experimental results demonstrate that DIIF can be integrated with implicit arbitrary-scale SR methods and achieves SOTA SR performance with significantly superior computational efficiency, thereby opening a path for real-time arbitrary-scale image representation. Our code can be found at https://github.com/HeZongyao/DIIF.