 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Learned Video Compression via Low-Resolution Representation Learning
Paper and Code
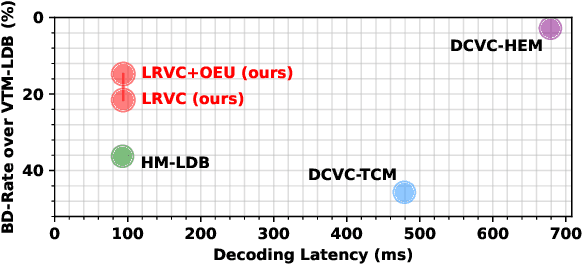

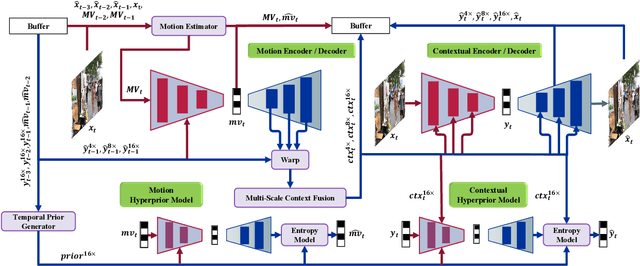

In recent years, the field of learned video compression has witnessed rapid advancement, exemplified by the latest neural video codecs DCVC-DC that has outperformed the upcoming next-generation codec ECM in terms of compression ratio. Despite this, learned video compression frameworks often exhibit low encoding and decoding speeds primarily due to their increased computational complexity and unnecessary high-resolution spatial operations, which hugely hinder their applications in reality. In this work, we introduce an efficiency-optimized framework for learned video compression that focuses on low-resolution representation learning, aiming to significantly enhance the encoding and decoding speeds. Firstly, we diminish the computational load by reducing the resolution of inter-frame propagated features obtained from reused features of decoded frames, including I-frames. We implement a joint training strategy for both the I-frame and P-frame models, further improving the compression ratio. Secondly, our approach efficiently leverages multi-frame priors for parameter prediction, minimizing computation at the decoding end. Thirdly, we revisit the application of the Online Encoder Update (OEU) strategy for high-resolution sequences, achieving notable improvements in compression ratio without compromising decoding efficiency. Our efficiency-optimized framework has significantly improved the balance between compression ratio and speed for learned video compression. In comparison to traditional codecs, our method achieves performance levels on par with the low-decay P configuration of the H.266 reference software VTM. Furthermore, when contrasted with DCVC-HEM, our approach delivers a comparable compression ratio while boosting encoding and decoding speeds by a factor of 3 and 7, respectively. On RTX 2080Ti, our method can decode each 1080p frame under 100ms.