 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
Oct 29, 2025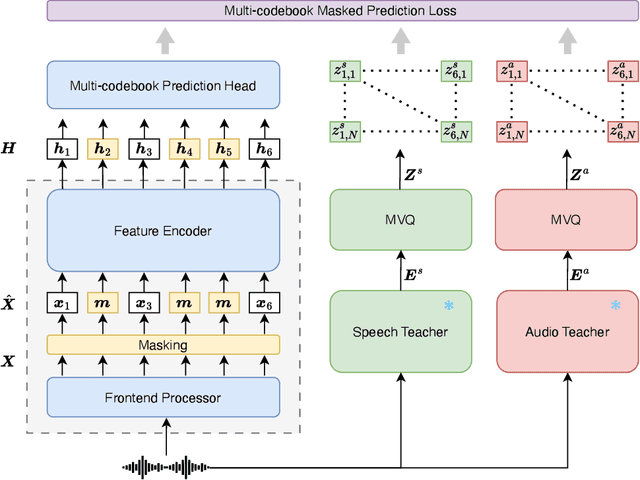

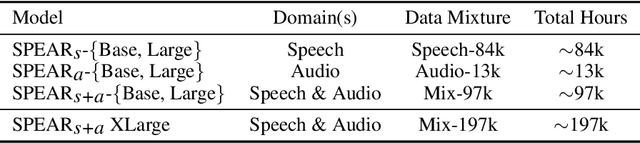
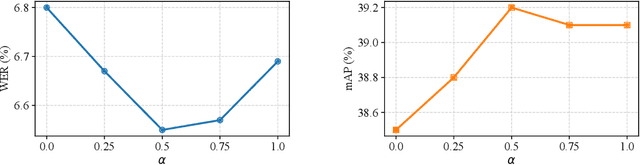
Self-Supervised Learning (SSL) excels at learning generic representations of acoustic signals, yet prevailing methods remain domain-specific, tailored to either speech or general audio, hindering the development of a unified representation model with a comprehensive capability over both domains. To address this, we present SPEAR (SPEech and Audio Representations), the first SSL framework to successfully learn unified speech and audio representations from a mixture of speech and audio data. SPEAR proposes a unified pre-training objective based on masked prediction of fine-grained discrete tokens for both speech and general audio. These tokens are derived from continuous speech and audio representations using a Multi-codebook Vector Quantisation (MVQ) method, retaining rich acoustic detail essential for modelling both speech and complex audio events. SPEAR is applied to pre-train both single-domain and unified speech-and-audio SSL models. Our speech-domain model establishes a new state-of-the-art on the SUPERB benchmark, a speech processing benchmark for SSL models, matching or surpassing the highly competitive WavLM Large on 12 out of 15 tasks with the same pre-training corpora and a similar model size. Crucially, our unified model learns complementary features and demonstrates comprehensive capabilities across two major benchmarks, SUPERB and HEAR, for evaluating audio representations. By further scaling up the model size and pre-training data, we present a unified model with 600M parameters that excels in both domains, establishing it as one of the most powerful and versatile open-source SSL models for auditory understanding. The inference code and pre-trained models will be made publicly available.
Towards Cross-Task Suicide Risk Detection via Speech LLM
Sep 26, 2025Suicide risk among adolescents remains a critical public health concern, and speech provides a non-invasive and scalable approach for its detection. Existing approaches, however, typically focus on one single speech assessment task at a time. This paper, for the first time, investigates cross-task approaches that unify diverse speech suicide risk assessment tasks within a single model. Specifically, we leverage a speech large language model as the backbone and incorporate a mixture of DoRA experts (MoDE) approach to capture complementary cues across diverse assessments dynamically. The proposed approach was tested on 1,223 participants across ten spontaneous speech tasks. Results demonstrate that MoDE not only achieves higher detection accuracy than both single-task specialised models and conventional joint-tuning approaches, but also provides better confidence calibration, which is especially important for medical detection tasks.
Speaker Anonymisation for Speech-based Suicide Risk Detection
Sep 26, 2025



Adolescent suicide is a critical global health issue, and speech provides a cost-effective modality for automatic suicide risk detection. Given the vulnerable population, protecting speaker identity is particularly important, as speech itself can reveal personally identifiable information if the data is leaked or maliciously exploited. This work presents the first systematic study of speaker anonymisation for speech-based suicide risk detection. A broad range of anonymisation methods are investigated, including techniques based on traditional signal processing, neural voice conversion, and speech synthesis. A comprehensive evaluation framework is built to assess the trade-off between protecting speaker identity and preserving information essential for suicide risk detection. Results show that combining anonymisation methods that retain complementary information yields detection performance comparable to that of original speech, while achieving protection of speaker identity for vulnerable populations.
The 1st SpeechWellness Challenge: Detecting Suicidal Risk Among Adolescents
Jan 11, 2025The 1st SpeechWellness Challenge (SW1) aims to advance methods for detecting suicidal risk in adolescents using speech analysis techniques. Suicide among adolescents is a critical public health issue globally. Early detection of suicidal tendencies can lead to timely intervention and potentially save lives. Traditional methods of assessment often rely on self-reporting or clinical interviews, which may not always be accessible. The SW1 challenge addresses this gap by exploring speech as a non-invasive and readily available indicator of mental health. We release the SW1 dataset which contains speech recordings from 600 adolescents aged 10-18 years. By focusing on speech generated from natural tasks, the challenge seeks to uncover patterns and markers that correlate with suicidal risk.
Spontaneous Speech-Based Suicide Risk Detection Using Whisper and Large Language Models
Jun 06, 2024The early detection of suicide risk is important since it enables the intervention to prevent potential suicide attempts. This paper studies the automatic detection of suicide risk based on spontaneous speech from adolescents, and collects a Mandarin dataset with 15 hours of suicide speech from more than a thousand adolescents aged from ten to eighteen for our experiments. To leverage the diverse acoustic and linguistic features embedded in spontaneous speech, both the Whisper speech model and textual large language models (LLMs) are used for suicide risk detection. Both all-parameter finetuning and parameter-efficient finetuning approaches are used to adapt the pre-trained models for suicide risk detection, and multiple audio-text fusion approaches are evaluated to combine the representations of Whisper and the LLM. The proposed system achieves a detection accuracy of 0.807 and an F1-score of 0.846 on the test set with 119 subjects, indicating promising potential for real suicide risk detection applications.
Bayesian WeakS-to-Strong from Text Classification to Generation
May 24, 2024



Advances in large language models raise the question of how alignment techniques will adapt as models become increasingly complex and humans will only be able to supervise them weakly. Weak-to-Strong mimics such a scenario where weak model supervision attempts to harness the full capabilities of a much stronger model. This work extends Weak-to-Strong to WeakS-to-Strong by exploring an ensemble of weak models which simulate the variability in human opinions. Confidence scores are estimated using a Bayesian approach to guide the WeakS-to-Strong generalization. Furthermore, we extend the application of WeakS-to-Strong from text classification tasks to text generation tasks where more advanced strategies are investigated for supervision. Moreover, direct preference optimization is applied to advance the student model's preference learning, beyond the basic learning framework of teacher forcing. Results demonstrate the effectiveness of the proposed approach for the reliability of a strong student model, showing potential for superalignment.
Transferring speech-generic and depression-specific knowledge for Alzheimer's disease detection
Oct 06, 2023The detection of Alzheimer's disease (AD) from spontaneous speech has attracted increasing attention while the sparsity of training data remains an important issue. This paper handles the issue by knowledge transfer, specifically from both speech-generic and depression-specific knowledge. The paper first studies sequential knowledge transfer from generic foundation models pretrained on large amounts of speech and text data. A block-wise analysis is performed for AD diagnosis based on the representations extracted from different intermediate blocks of different foundation models. Apart from the knowledge from speech-generic representations, this paper also proposes to simultaneously transfer the knowledge from a speech depression detection task based on the high comorbidity rates of depression and AD. A parallel knowledge transfer framework is studied that jointly learns the information shared between these two tasks. Experimental results show that the proposed method improves AD and depression detection, and produces a state-of-the-art F1 score of 0.928 for AD diagnosis on the commonly used ADReSSo dataset.