 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Cross-Modal Flows for Few-Shot Learning
Oct 16, 2025Aligning features from different modalities, is one of the most fundamental challenges for cross-modal tasks. Although pre-trained vision-language models can achieve a general alignment between image and text, they often require parameter-efficient fine-tuning (PEFT) for further adjustment. Today's PEFT methods (e.g., prompt tuning, LoRA-based, or adapter-based) always selectively fine-tune a subset of parameters, which can slightly adjust either visual or textual features, and avoid overfitting. In this paper, we are the first to highlight that all existing PEFT methods perform one-step adjustment. It is insufficient for complex (or difficult) datasets, where features of different modalities are highly entangled. To this end, we propose the first model-agnostic multi-step adjustment approach by learning a cross-modal velocity field: Flow Matching Alignment (FMA). Specifically, to ensure the correspondence between categories during training, we first utilize a fixed coupling strategy. Then, we propose a noise augmentation strategy to alleviate the data scarcity issue. Finally, we design an early-stopping solver, which terminates the transformation process earlier, improving both efficiency and accuracy. Compared with one-step PEFT methods, FMA has the multi-step rectification ability to achieve more precise and robust alignment. Extensive results have demonstrated that FMA can consistently yield significant performance gains across various benchmarks and backbones, particularly on challenging datasets.
Combing Text-based and Drag-based Editing for Precise and Flexible Image Editing
Oct 04, 2024



Precise and flexible image editing remains a fundamental challenge in computer vision. Based on the modified areas, most editing methods can be divided into two main types: global editing and local editing. In this paper, we choose the two most common editing approaches (ie text-based editing and drag-based editing) and analyze their drawbacks. Specifically, text-based methods often fail to describe the desired modifications precisely, while drag-based methods suffer from ambiguity. To address these issues, we proposed \textbf{CLIPDrag}, a novel image editing method that is the first to combine text and drag signals for precise and ambiguity-free manipulations on diffusion models. To fully leverage these two signals, we treat text signals as global guidance and drag points as local information. Then we introduce a novel global-local motion supervision method to integrate text signals into existing drag-based methods by adapting a pre-trained language-vision model like CLIP. Furthermore, we also address the problem of slow convergence in CLIPDrag by presenting a fast point-tracking method that enforces drag points moving toward correct directions. Extensive experiments demonstrate that CLIPDrag outperforms existing single drag-based methods or text-based methods.
Causal Distillation for Alleviating Performance Heterogeneity in Recommender Systems
May 31, 2024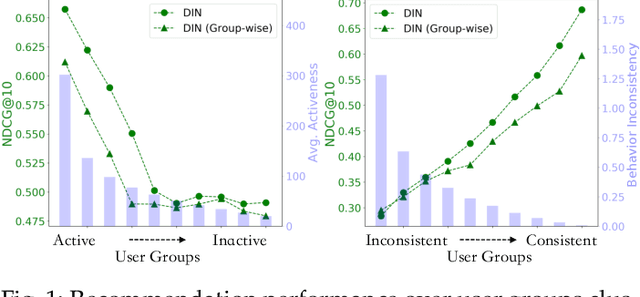
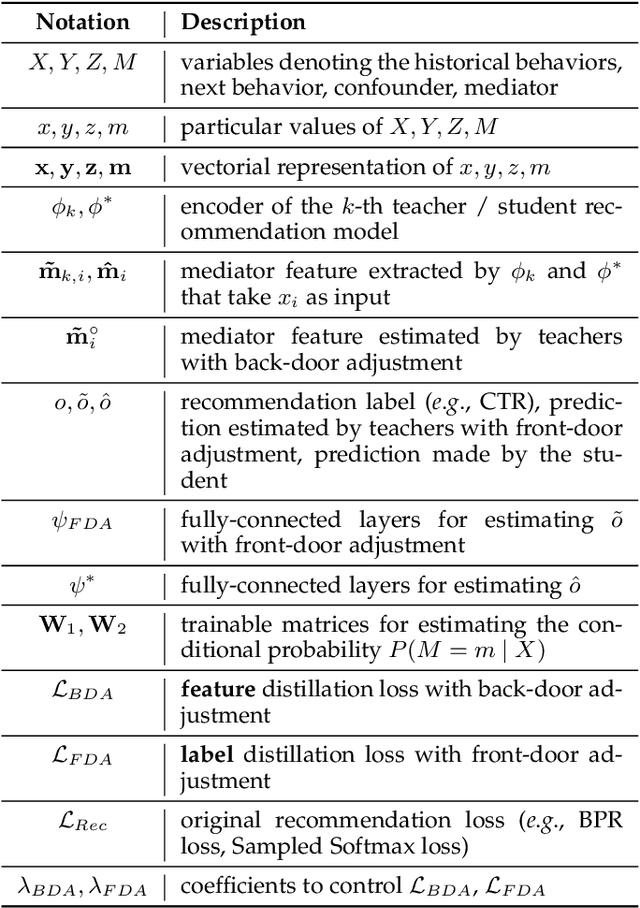
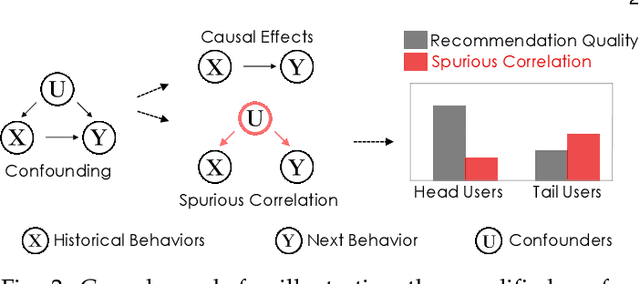
Recommendation performance usually exhibits a long-tail distribution over users -- a small portion of head users enjoy much more accurate recommendation services than the others. We reveal two sources of this performance heterogeneity problem: the uneven distribution of historical interactions (a natural source); and the biased training of recommender models (a model source). As addressing this problem cannot sacrifice the overall performance, a wise choice is to eliminate the model bias while maintaining the natural heterogeneity. The key to debiased training lies in eliminating the effect of confounders that influence both the user's historical behaviors and the next behavior. The emerging causal recommendation methods achieve this by modeling the causal effect between user behaviors, however potentially neglect unobserved confounders (\eg, friend suggestions) that are hard to measure in practice. To address unobserved confounders, we resort to the front-door adjustment (FDA) in causal theory and propose a causal multi-teacher distillation framework (CausalD). FDA requires proper mediators in order to estimate the causal effects of historical behaviors on the next behavior. To achieve this, we equip CausalD with multiple heterogeneous recommendation models to model the mediator distribution. Then, the causal effect estimated by FDA is the expectation of recommendation prediction over the mediator distribution and the prior distribution of historical behaviors, which is technically achieved by multi-teacher ensemble. To pursue efficient inference, CausalD further distills multiple teachers into one student model to directly infer the causal effect for making recommendations.