 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph neural networks and attention-based CNN-LSTM for protein classification
Apr 20, 2022
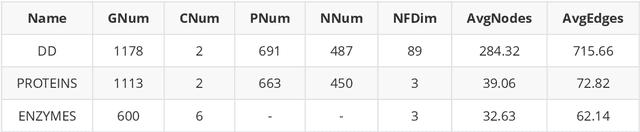
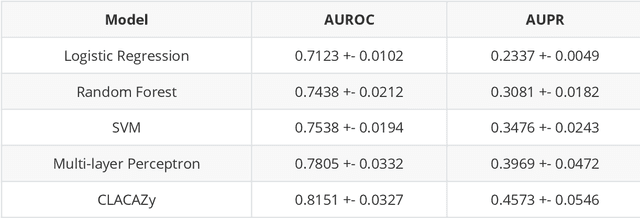
This paper focuses on three critical problems on protein classification. Firstly, Carbohydrate-active enzyme (CAZyme) classification can help people to understand the properties of enzymes. However, one CAZyme may belong to several classes. This leads to Multi-label CAZyme classification. Secondly, to capture information from the secondary structure of protein, protein classification is modeled as graph classification problem. Thirdly, compound-protein interactions prediction employs graph learning for compound with sequential embedding for protein. This can be seen as classification task for compound-protein pairs. This paper proposes three models for protein classification. Firstly, this paper proposes a Multi-label CAZyme classification model using CNN-LSTM with Attention mechanism. Secondly, this paper proposes a variational graph autoencoder based subspace learning model for protein graph classification. Thirdly, this paper proposes graph isomorphism networks (GIN) and Attention-based CNN-LSTM for compound-protein interactions prediction, as well as comparing GIN with graph convolution networks (GCN) and graph attention networks (GAT) in this task. The proposed models are effective for protein classification. Source code and data are available at https://github.com/zshicode/GNN-AttCL-protein. Besides, this repository collects and collates the benchmark datasets with respect to above problems, including CAZyme classification, enzyme protein graph classification, compound-protein interactions prediction, drug-target affinities prediction and drug-drug interactions prediction. Hence, the usage for evaluation by benchmark datasets can be more conveniently.
Attention-based CNN-LSTM and XGBoost hybrid model for stock prediction
Apr 06, 2022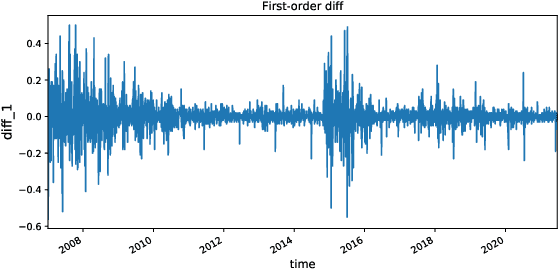
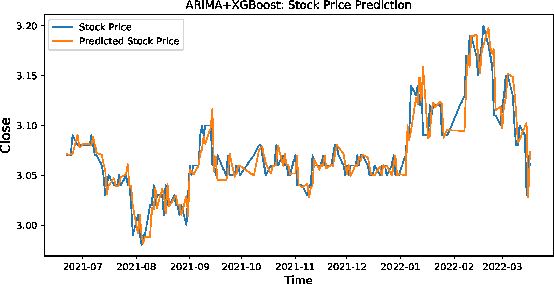

Stock market plays an important role in the economic development. Due to the complex volatility of the stock market, the research and prediction on the change of the stock price, can avoid the risk for the investors. The traditional time series model ARIMA can not describe the nonlinearity, and can not achieve satisfactory results in the stock prediction. As neural networks are with strong nonlinear generalization ability, this paper proposes an attention-based CNN-LSTM and XGBoost hybrid model to predict the stock price. The model constructed in this paper integrates the time series model, the Convolutional Neural Networks with Attention mechanism, the Long Short-Term Memory network, and XGBoost regressor in a non-linear relationship, and improves the prediction accuracy. The model can fully mine the historical information of the stock market in multiple periods. The stock data is first preprocessed through ARIMA. Then, the deep learning architecture formed in pretraining-finetuning framework is adopted. The pre-training model is the Attention-based CNN-LSTM model based on sequence-to-sequence framework. The model first uses convolution to extract the deep features of the original stock data, and then uses the Long Short-Term Memory networks to mine the long-term time series features. Finally, the XGBoost model is adopted for fine-tuning. The results show that the hybrid model is more effective and the prediction accuracy is relatively high, which can help investors or institutions to make decisions and achieve the purpose of expanding return and avoiding risk. Source code is available at https://github.com/zshicode/Attention-CLX-stock-prediction.
Differential equation and probability inspired graph neural networks for latent variable learning
Feb 28, 2022

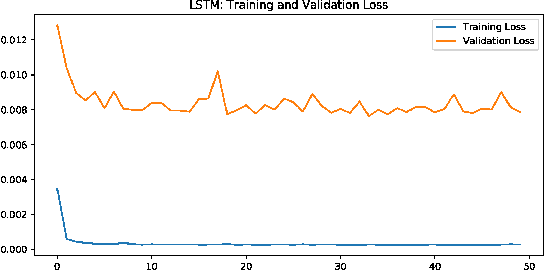
Probabilistic theory and differential equation are powerful tools for the interpretability and guidance of the design of machine learning models, especially for illuminating the mathematical motivation of learning latent variable from observation. State estimation and subspace learning are two classical problems in latent variable learning. State estimation solves optimal value for latent variable (i.e. state) from noised observation. Subspace learning maps high-dimensional features on low-dimensional subspace to capture efficient representation. Graphs are widely applied for modeling latent variable learning problems, and graph neural networks implement deep learning architectures on graphs. Inspired by probabilistic theory and differential equations, this paper proposes graph neural networks to solve state estimation and subspace learning problems. This paper conducts theoretical studies, and adopts empirical studies on several tasks, including text classification, protein classification, stock prediction and state estimation for robotics. Experiments illustrate that the proposed graph neural networks are superior to the current methods. Source code of this paper is available at https://github.com/zshicode/Latent-variable-GNN.
Incorporating Transformer and LSTM to Kalman Filter with EM algorithm for state estimation
May 25, 2021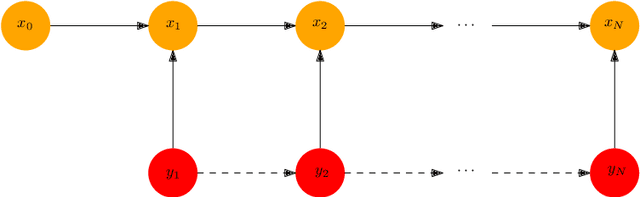
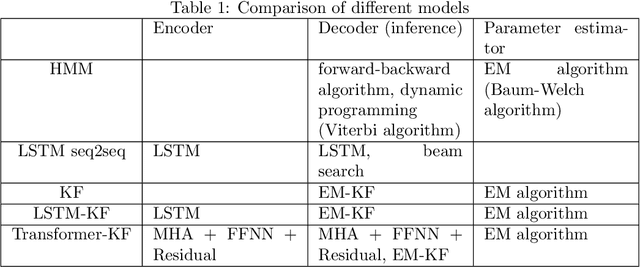
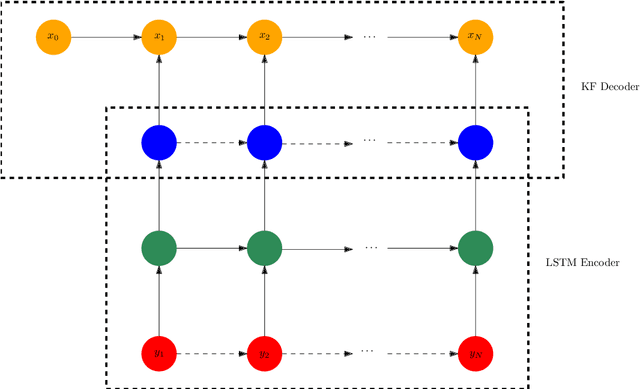

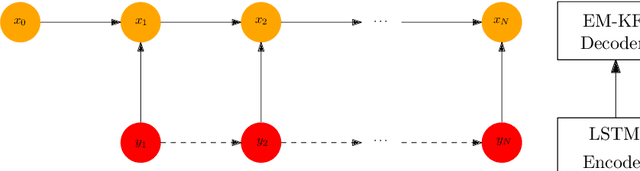
Kalman Filter requires the true parameters of the model and solves optimal state estimation recursively. Expectation Maximization (EM) algorithm is applicable for estimating the parameters of the model that are not available before Kalman filtering, which is EM-KF algorithm. To improve the preciseness of EM-KF algorithm, the author presents a state estimation method by combining the Long-Short Term Memory network (LSTM), Transformer and EM-KF algorithm in the framework of Encoder-Decoder in Sequence to Sequence (seq2seq). Simulation on a linear mobile robot model demonstrates that the new method is more accurate. Source code of this paper is available at https://github.com/zshicode/Deep-Learning-Based-State-Estimation.
Bidirectional LSTM-CRF Attention-based Model for Chinese Word Segmentation
May 20, 2021
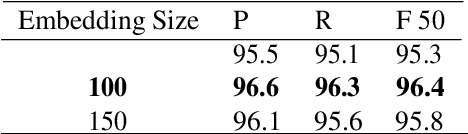
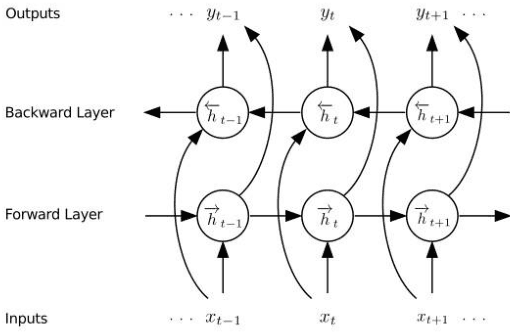
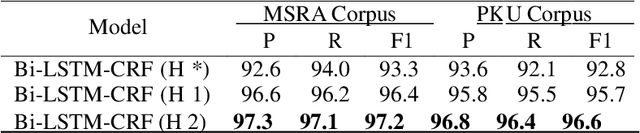
Chinese word segmentation (CWS) is the basic of Chinese natural language processing (NLP). The quality of word segmentation will directly affect the rest of NLP tasks. Recently, with the artificial intelligence tide rising again, Long Short-Term Memory (LSTM) neural network, as one of easily modeling in sequence, has been widely utilized in various kinds of NLP tasks, and functions well. Attention mechanism is an ingenious method to solve the memory compression problem on LSTM. Furthermore, inspired by the powerful abilities of bidirectional LSTM models for modeling sequence and CRF model for decoding, we propose a Bidirectional LSTM-CRF Attention-based Model in this paper. Experiments on PKU and MSRA benchmark datasets show that our model performs better than the baseline methods modeling by other neural networks.