 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopological Deep Learning for Speech Data
May 27, 2025Topological data analysis (TDA) offers novel mathematical tools for deep learning. Inspired by Carlsson et al., this study designs topology-aware convolutional kernels that significantly improve speech recognition networks. Theoretically, by investigating orthogonal group actions on kernels, we establish a fiber-bundle decomposition of matrix spaces, enabling new filter generation methods. Practically, our proposed Orthogonal Feature (OF) layer achieves superior performance in phoneme recognition, particularly in low-noise scenarios, while demonstrating cross-domain adaptability. This work reveals TDA's potential in neural network optimization, opening new avenues for mathematics-deep learning interdisciplinary studies.
G4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Mar 02, 2024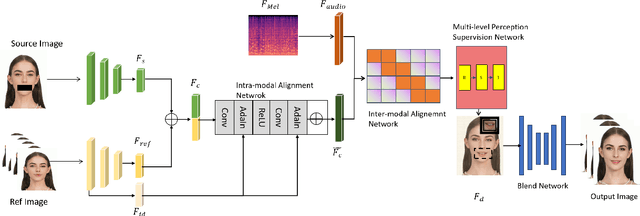



Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.
Topology combined machine learning for consonant recognition
Nov 26, 2023



In artificial-intelligence-aided signal processing, existing deep learning models often exhibit a black-box structure, and their validity and comprehensibility remain elusive. The integration of topological methods, despite its relatively nascent application, serves a dual purpose of making models more interpretable as well as extracting structural information from time-dependent data for smarter learning. Here, we provide a transparent and broadly applicable methodology, TopCap, to capture the most salient topological features inherent in time series for machine learning. Rooted in high-dimensional ambient spaces, TopCap is capable of capturing features rarely detected in datasets with low intrinsic dimensionality. Applying time-delay embedding and persistent homology, we obtain descriptors which encapsulate information such as the vibration of a time series, in terms of its variability of frequency, amplitude, and average line, demonstrated with simulated data. This information is then vectorised and fed into multiple machine learning algorithms such as k-nearest neighbours and support vector machine. Notably, in classifying voiced and voiceless consonants, TopCap achieves an accuracy exceeding 96% and is geared towards designing topological convolutional layers for deep learning of speech and audio signals.