 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG4G:A Generic Framework for High Fidelity Talking Face Generation with Fine-grained Intra-modal Alignment
Mar 02, 2024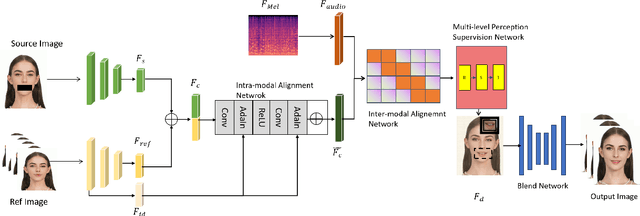



Despite numerous completed studies, achieving high fidelity talking face generation with highly synchronized lip movements corresponding to arbitrary audio remains a significant challenge in the field. The shortcomings of published studies continue to confuse many researchers. This paper introduces G4G, a generic framework for high fidelity talking face generation with fine-grained intra-modal alignment. G4G can reenact the high fidelity of original video while producing highly synchronized lip movements regardless of given audio tones or volumes. The key to G4G's success is the use of a diagonal matrix to enhance the ordinary alignment of audio-image intra-modal features, which significantly increases the comparative learning between positive and negative samples. Additionally, a multi-scaled supervision module is introduced to comprehensively reenact the perceptional fidelity of original video across the facial region while emphasizing the synchronization of lip movements and the input audio. A fusion network is then used to further fuse the facial region and the rest. Our experimental results demonstrate significant achievements in reenactment of original video quality as well as highly synchronized talking lips. G4G is an outperforming generic framework that can produce talking videos competitively closer to ground truth level than current state-of-the-art methods.