 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRich-Media Re-Ranker: A User Satisfaction-Driven LLM Re-ranking Framework for Rich-Media Search
Feb 05, 2026Re-ranking plays a crucial role in modern information search systems by refining the ranking of initial search results to better satisfy user information needs. However, existing methods show two notable limitations in improving user search satisfaction: inadequate modeling of multifaceted user intents and neglect of rich side information such as visual perception signals. To address these challenges, we propose the Rich-Media Re-Ranker framework, which aims to enhance user search satisfaction through multi-dimensional and fine-grained modeling. Our approach begins with a Query Planner that analyzes the sequence of query refinements within a session to capture genuine search intents, decomposing the query into clear and complementary sub-queries to enable broader coverage of users' potential intents. Subsequently, moving beyond primary text content, we integrate richer side information of candidate results, including signals modeling visual content generated by the VLM-based evaluator. These comprehensive signals are then processed alongside carefully designed re-ranking principle that considers multiple facets, including content relevance and quality, information gain, information novelty, and the visual presentation of cover images. Then, the LLM-based re-ranker performs the holistic evaluation based on these principles and integrated signals. To enhance the scenario adaptability of the VLM-based evaluator and the LLM-based re-ranker, we further enhance their capabilities through multi-task reinforcement learning. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art baselines. Notably, the proposed framework has been deployed in a large-scale industrial search system, yielding substantial improvements in online user engagement rates and satisfaction metrics.
MBCAL: A Simple and Efficient Reinforcement Learning Method for Recommendation Systems
Nov 06, 2019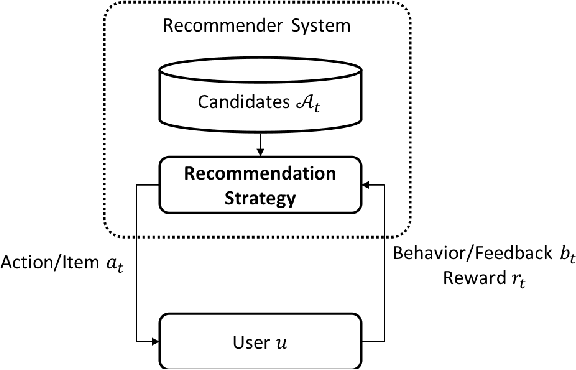

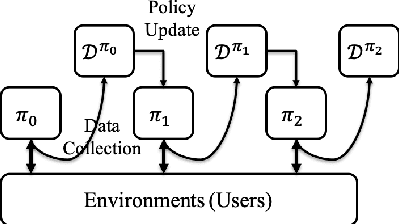
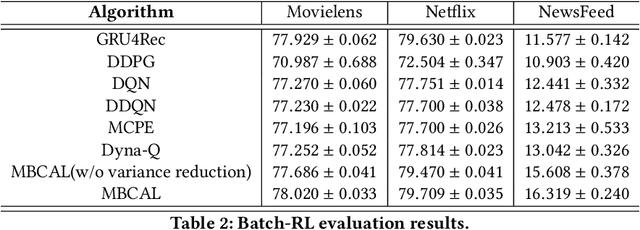
It has been widely regarded that only considering the immediate user feedback is not sufficient for modern industrial recommendation systems. Many previous works attempt to maximize the long term rewards with Reinforcement Learning(RL). However, model-free RL suffers from problems including significant variance in gradient, long convergence period, and requirement of sophisticated online infrastructures. While model-based RL provides a sample-efficient choice, the cost of planning in an online system is unacceptable. To achieve high sample efficiency in practical situations, we propose a novel model-based reinforcement learning method, namely the model-based counterfactual advantage learning(MBCAL). In the proposed method, a masking item is introduced in the environment model learning. With the masking item and the environment model, we introduce the counterfactual future advantage, which eliminates most of the noises in long term rewards. The proposed method selects through approximating the immediate reward and future advantage separately. It is easy to implement, yet it requires reasonable cost in both training and inference processes. In the experiments, we compare our methods with several baselines, including supervised learning, model-free RL, and other model-based RL methods in carefully designed experiments. Results show that our method transcends all the baselines in both sample efficiency and asymptotic performance.