 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMBCAL: A Simple and Efficient Reinforcement Learning Method for Recommendation Systems
Paper and Code
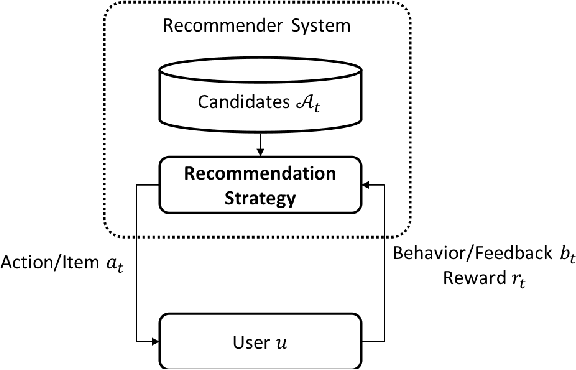

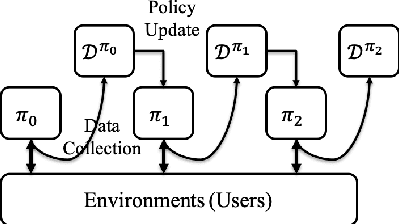
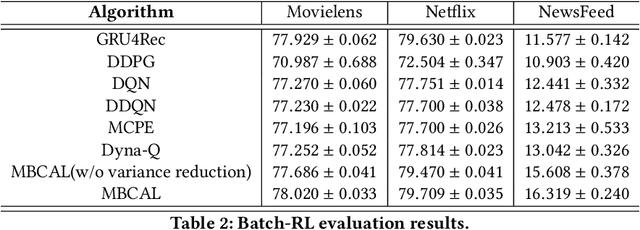
It has been widely regarded that only considering the immediate user feedback is not sufficient for modern industrial recommendation systems. Many previous works attempt to maximize the long term rewards with Reinforcement Learning(RL). However, model-free RL suffers from problems including significant variance in gradient, long convergence period, and requirement of sophisticated online infrastructures. While model-based RL provides a sample-efficient choice, the cost of planning in an online system is unacceptable. To achieve high sample efficiency in practical situations, we propose a novel model-based reinforcement learning method, namely the model-based counterfactual advantage learning(MBCAL). In the proposed method, a masking item is introduced in the environment model learning. With the masking item and the environment model, we introduce the counterfactual future advantage, which eliminates most of the noises in long term rewards. The proposed method selects through approximating the immediate reward and future advantage separately. It is easy to implement, yet it requires reasonable cost in both training and inference processes. In the experiments, we compare our methods with several baselines, including supervised learning, model-free RL, and other model-based RL methods in carefully designed experiments. Results show that our method transcends all the baselines in both sample efficiency and asymptotic performance.