 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification via Hölder Divergence for Multi-View Representation Learning
Oct 29, 2024
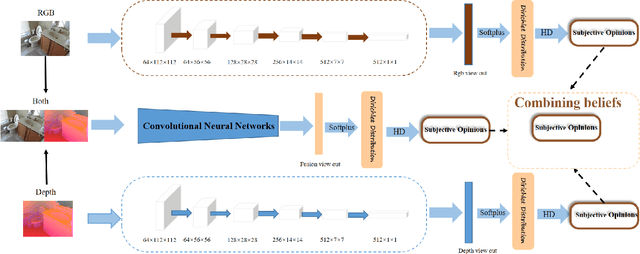
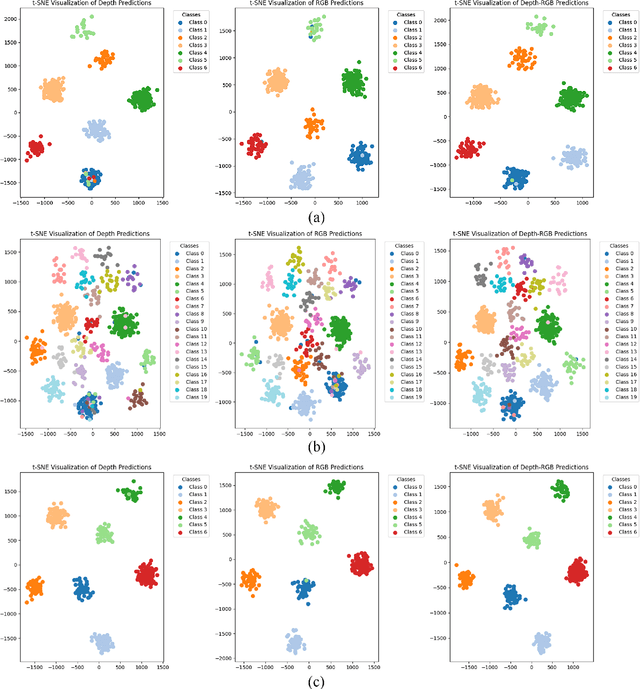

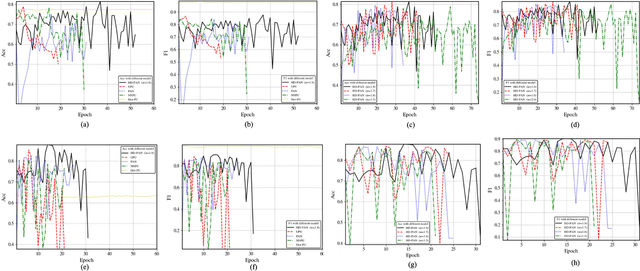
Evidence-based deep learning represents a burgeoning paradigm for uncertainty estimation, offering reliable predictions with negligible extra computational overheads. Existing methods usually adopt Kullback-Leibler divergence to estimate the uncertainty of network predictions, ignoring domain gaps among various modalities. To tackle this issue, this paper introduces a novel algorithm based on H\"older Divergence (HD) to enhance the reliability of multi-view learning by addressing inherent uncertainty challenges from incomplete or noisy data. Generally, our method extracts the representations of multiple modalities through parallel network branches, and then employs HD to estimate the prediction uncertainties. Through the Dempster-Shafer theory, integration of uncertainty from different modalities, thereby generating a comprehensive result that considers all available representations. Mathematically, HD proves to better measure the ``distance'' between real data distribution and predictive distribution of the model and improve the performances of multi-class recognition tasks. Specifically, our method surpass the existing state-of-the-art counterparts on all evaluating benchmarks. We further conduct extensive experiments on different backbones to verify our superior robustness. It is demonstrated that our method successfully pushes the corresponding performance boundaries. Finally, we perform experiments on more challenging scenarios, \textit{i.e.}, learning with incomplete or noisy data, revealing that our method exhibits a high tolerance to such corrupted data.
Semi-Supervised Disease Classification based on Limited Medical Image Data
May 07, 2024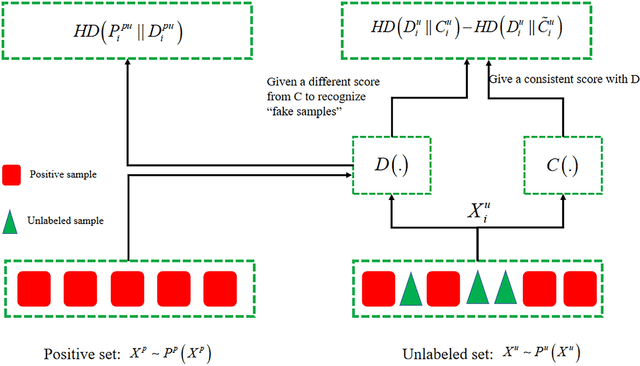
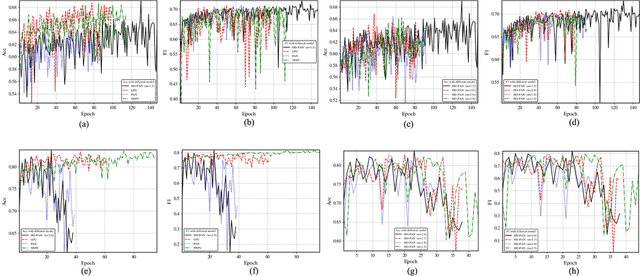
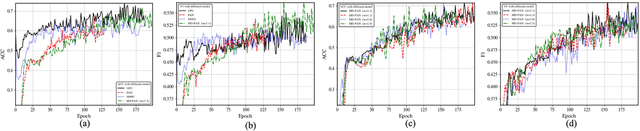
In recent years, significant progress has been made in the field of learning from positive and unlabeled examples (PU learning), particularly in the context of advancing image and text classification tasks. However, applying PU learning to semi-supervised disease classification remains a formidable challenge, primarily due to the limited availability of labeled medical images. In the realm of medical image-aided diagnosis algorithms, numerous theoretical and practical obstacles persist. The research on PU learning for medical image-assisted diagnosis holds substantial importance, as it aims to reduce the time spent by professional experts in classifying images. Unlike natural images, medical images are typically accompanied by a scarcity of annotated data, while an abundance of unlabeled cases exists. Addressing these challenges, this paper introduces a novel generative model inspired by H\"older divergence, specifically designed for semi-supervised disease classification using positive and unlabeled medical image data. In this paper, we present a comprehensive formulation of the problem and establish its theoretical feasibility through rigorous mathematical analysis. To evaluate the effectiveness of our proposed approach, we conduct extensive experiments on five benchmark datasets commonly used in PU medical learning: BreastMNIST, PneumoniaMNIST, BloodMNIST, OCTMNIST, and AMD. The experimental results clearly demonstrate the superiority of our method over existing approaches based on KL divergence. Notably, our approach achieves state-of-the-art performance on all five disease classification benchmarks. By addressing the limitations imposed by limited labeled data and harnessing the untapped potential of unlabeled medical images, our novel generative model presents a promising direction for enhancing semi-supervised disease classification in the field of medical image analysis.