 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Spike-driven Transformer for High-performance Drone-View Geo-Localization
Dec 22, 2025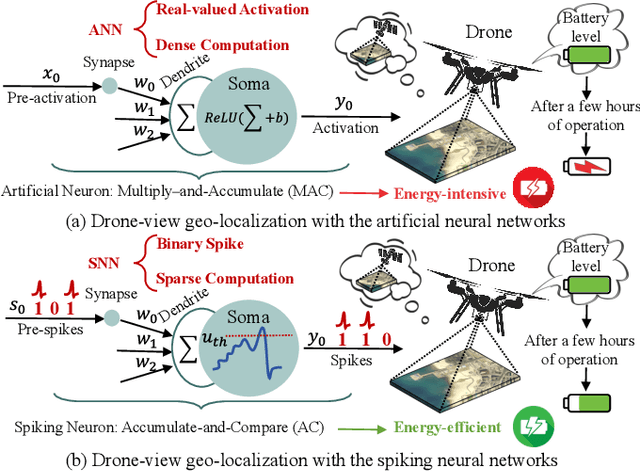
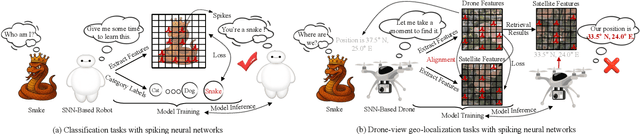
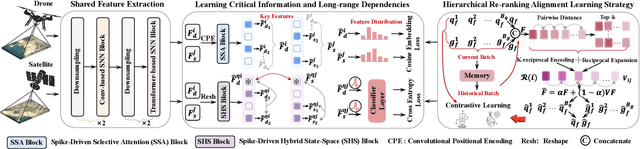
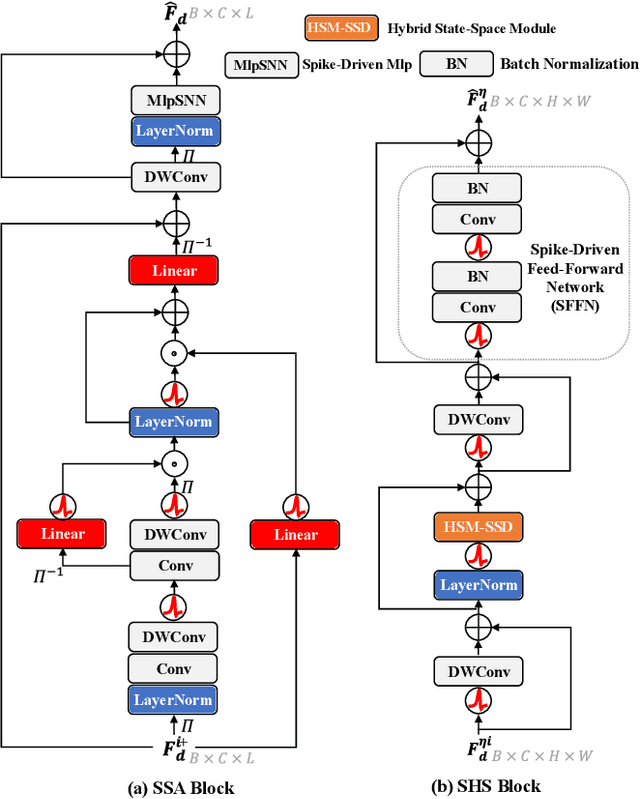
Traditional drone-view geo-localization (DVGL) methods based on artificial neural networks (ANNs) have achieved remarkable performance. However, ANNs rely on dense computation, which results in high power consumption. In contrast, spiking neural networks (SNNs), which benefit from spike-driven computation, inherently provide low power consumption. Regrettably, the potential of SNNs for DVGL has yet to be thoroughly investigated. Meanwhile, the inherent sparsity of spike-driven computation for representation learning scenarios also results in loss of critical information and difficulties in learning long-range dependencies when aligning heterogeneous visual data sources. To address these, we propose SpikeViMFormer, the first SNN framework designed for DVGL. In this framework, a lightweight spike-driven transformer backbone is adopted to extract coarse-grained features. To mitigate the loss of critical information, the spike-driven selective attention (SSA) block is designed, which uses a spike-driven gating mechanism to achieve selective feature enhancement and highlight discriminative regions. Furthermore, a spike-driven hybrid state space (SHS) block is introduced to learn long-range dependencies using a hybrid state space. Moreover, only the backbone is utilized during the inference stage to reduce computational cost. To ensure backbone effectiveness, a novel hierarchical re-ranking alignment learning (HRAL) strategy is proposed. It refines features via neighborhood re-ranking and maintains cross-batch consistency to directly optimize the backbone. Experimental results demonstrate that SpikeViMFormer outperforms state-of-the-art SNNs. Compared with advanced ANNs, it also achieves competitive performance.Our code is available at https://github.com/ISChenawei/SpikeViMFormer
From Limited Labels to Open Domains: An Efficient Learning Paradigm for UAV-view Geo-Localization
Mar 10, 2025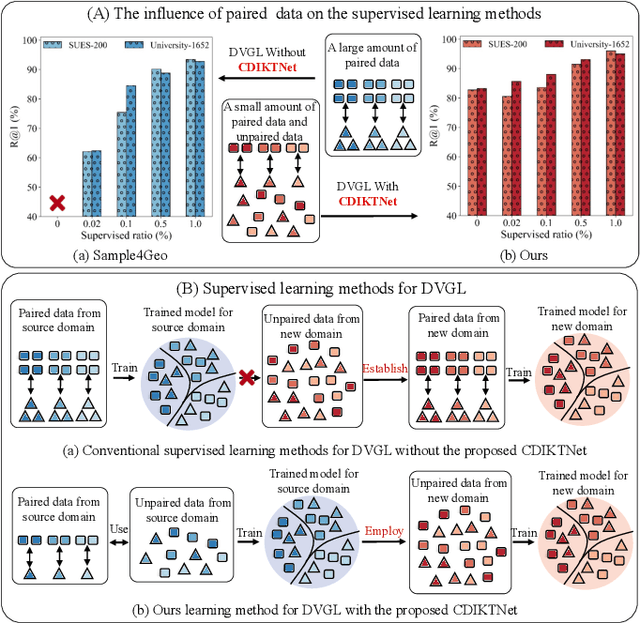
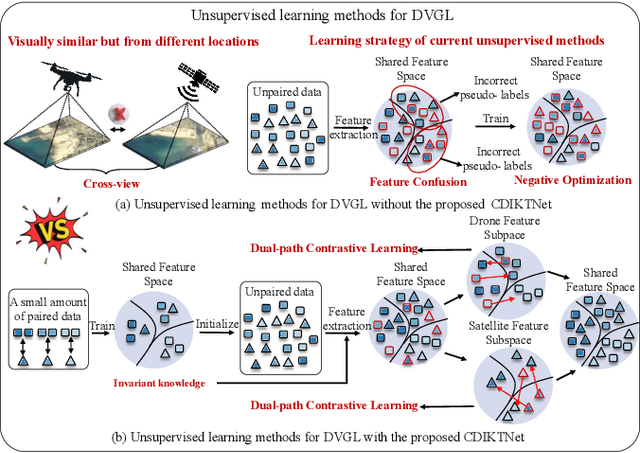
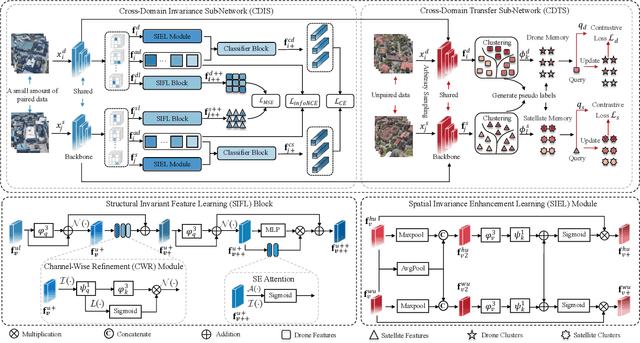
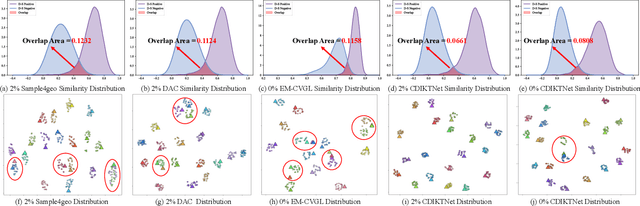
Traditional UAV-view Geo-Localization (UVGL) supervised paradigms are constrained by the strict reliance on paired data for positive sample selection, which limits their ability to learn cross-view domain-invariant representations from unpaired data. Moreover, it is necessary to reconstruct the pairing relationship with expensive re-labeling costs for scenario-specific training when deploying in a new domain, which fails to meet the practical demands of open-environment applications. To address this issue, we propose a novel cross-domain invariance knowledge transfer network (CDIKTNet), which comprises a cross-domain invariance sub-network and a cross-domain transfer sub-network to realize a closed-loop framework of invariance feature learning and knowledge transfer. The cross-domain invariance sub-network is utilized to construct an essentially shared feature space across domains by learning structural invariance and spatial invariance in cross-view features. Meanwhile, the cross-domain transfer sub-network uses these invariant features as anchors and employs a dual-path contrastive memory learning mechanism to mine latent cross-domain correlation patterns in unpaired data. Extensive experiments demonstrate that our method achieves state-of-the-art performance under fully supervised conditions. More importantly, with merely 2\% paired data, our method exhibits performance comparable to existing supervised paradigms and possesses the ability to transfer directly to qualify for applications in the other scenarios completely without any prior pairing relationship.
Without Paired Labeled Data: An End-to-End Self-Supervised Paradigm for UAV-View Geo-Localization
Feb 17, 2025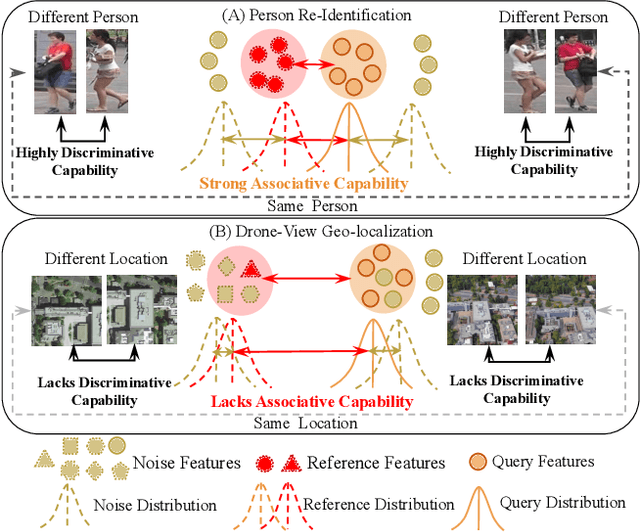
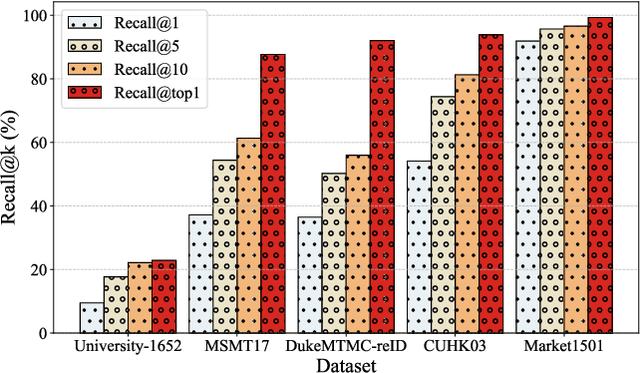
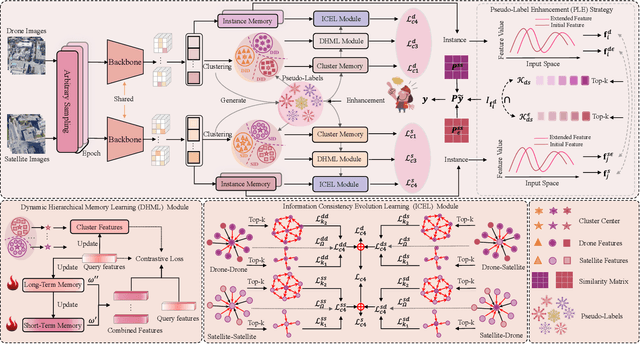
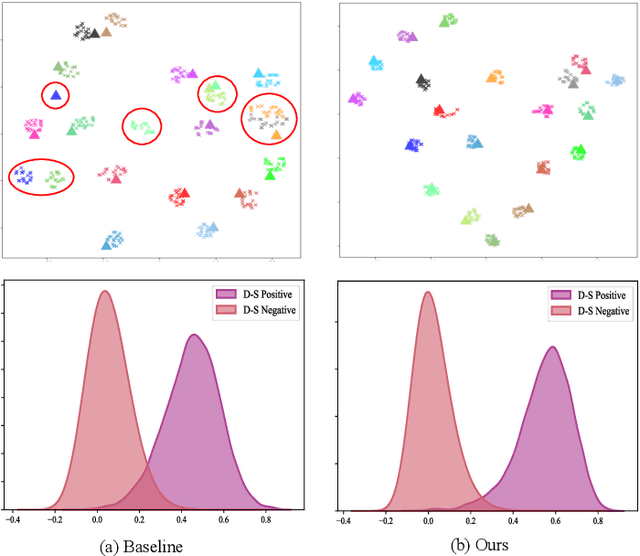
UAV-View Geo-Localization (UVGL) aims to ascertain the precise location of a UAV by retrieving the most similar GPS-tagged satellite image. However, existing methods predominantly rely on supervised learning paradigms that necessitate annotated paired data for training, which incurs substantial annotation costs and impedes large-scale deployment. To overcome this limitation, we propose the Dynamic Memory-Driven and Neighborhood Information Learning (DMNIL) network, a lightweight end-to-end self-supervised framework for UAV-view geo-localization. The DMNIL framework utilizes a dual-path clustering-based contrastive learning architecture as its baseline to model intra-view structural relationships, enhancing feature consistency and discriminability. Additionally, a dynamic memory-driven hierarchical learning module is proposed to progressively mine local and global information, reinforcing multi-level feature associations to improve model robustness. To bridge the domain gap between UAV and satellite views, we design an information-consistent evolutionary learning mechanism that systematically explores latent correlations within intra-view neighborhoods and across cross-view domains, ultimately constructing a unified cross-view feature representation space. Extensive experiments on three benchmarks (University-1652, SUES-200, and DenseUAV) demonstrate that DMNIL achieves competitive performance against state-of-the-art supervised methods while maintaining computational efficiency. Notably, this superiority is attained without relying on paired training data, underscoring the framework's practicality for real-world deployment. Codes will be released soon.
Multi-Level Embedding and Alignment Network with Consistency and Invariance Learning for Cross-View Geo-Localization
Dec 19, 2024Cross-View Geo-Localization (CVGL) involves determining the localization of drone images by retrieving the most similar GPS-tagged satellite images. However, the imaging gaps between platforms are often significant and the variations in viewpoints are substantial, which limits the ability of existing methods to effectively associate cross-view features and extract consistent and invariant characteristics. Moreover, existing methods often overlook the problem of increased computational and storage requirements when improving model performance. To handle these limitations, we propose a lightweight enhanced alignment network, called the Multi-Level Embedding and Alignment Network (MEAN). The MEAN network uses a progressive multi-level enhancement strategy, global-to-local associations, and cross-domain alignment, enabling feature communication across levels. This allows MEAN to effectively connect features at different levels and learn robust cross-view consistent mappings and modality-invariant features. Moreover, MEAN adopts a shallow backbone network combined with a lightweight branch design, effectively reducing parameter count and computational complexity. Experimental results on the University-1652 and SUES-200 datasets demonstrate that MEAN reduces parameter count by 62.17% and computational complexity by 70.99% compared to state-of-the-art models, while maintaining competitive or even superior performance. The codes will be released soon.
A Novel Self-Organizing PID Approach for Controlling Mobile Robot Locomotion
Dec 17, 2019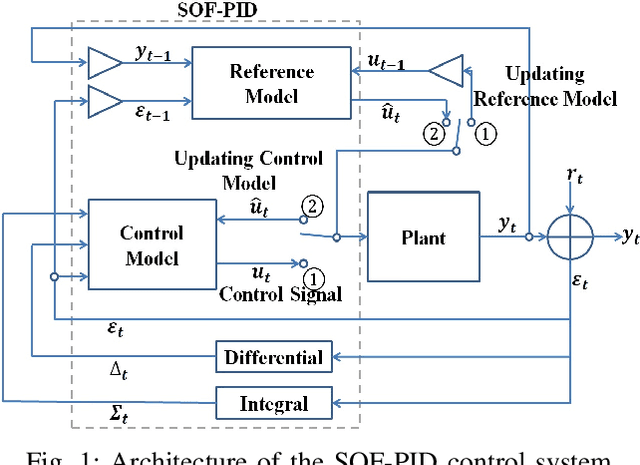
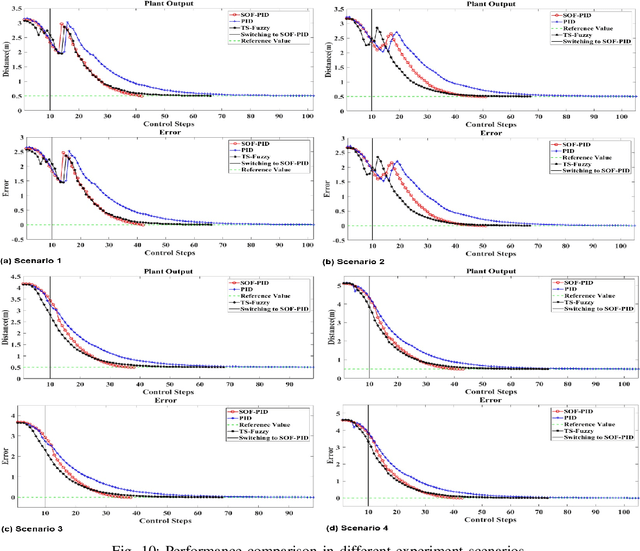

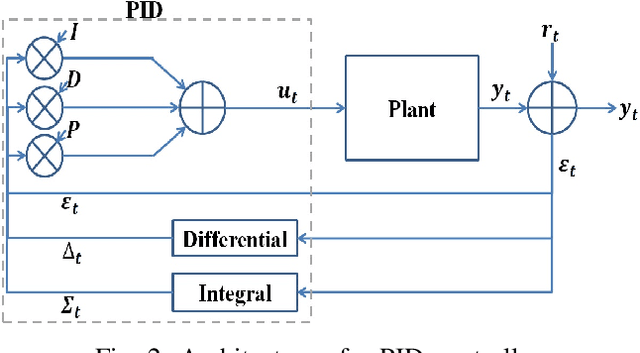
A novel self-organizing fuzzy proportional-integral-derivative (SOF-PID) control system is proposed in this paper. The proposed system consists of a pair of control and reference models, both of which are implemented by a first-order autonomous learning multiple model (ALMMo) neuro-fuzzy system. The SOF-PID controller self-organizes and self-updates the structures and meta-parameters of both the control and reference models during the control process "on the fly". This gives the SOF-PID control system the capability of quickly adapting to entirely new operating environments without a full re-training. Moreover, the SOF-PID control system is free from user- and problem-specific parameters, and the uniform stability of the SOF-PID control system is theoretically guaranteed. Simulations and real-world experiments with mobile robots demonstrate the effectiveness and validity of the proposed SOF-PID control system.