 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace-Guided Sentiment Boundary Enhancement for Weakly-Supervised Temporal Sentiment Localization
Mar 16, 2026Point-level weakly-supervised temporal sentiment localization (P-WTSL) aims to detect sentiment-relevant segments in untrimmed multimodal videos using timestamp sentiment annotations, which greatly reduces the costly frame-level labeling. To further tackle the challenges of imprecise sentiment boundaries in P-WTSL, we propose the Face-guided Sentiment Boundary Enhancement Network (\textbf{FSENet}), a unified framework that leverages fine-grained facial features to guide sentiment localization. Specifically, our approach \textit{first} introduces the Face-guided Sentiment Discovery (FSD) module, which integrates facial features into multimodal interaction via dual-branch modeling for effective sentiment stimuli clues; We \textit{then} propose the Point-aware Sentiment Semantics Contrast (PSSC) strategy to discriminate sentiment semantics of candidate points (frame-level) near annotation points via contrastive learning, thereby enhancing the model's ability to recognize sentiment boundaries. At \textit{last}, we design the Boundary-aware Sentiment Pseudo-label Generation (BSPG) approach to convert sparse point annotations into temporally smooth supervisory pseudo-labels. Extensive experiments and visualizations on the benchmark demonstrate the effectiveness of our framework, achieving state-of-the-art performance under full supervision, video-level, and point-level weak supervision, thereby showcasing the strong generalization ability of our FSENet across different annotation settings.
EmoSEM: Segment and Explain Emotion Stimuli in Visual Art
Apr 22, 2025This paper focuses on a key challenge in visual art understanding: given an art image, the model pinpoints pixel regions that trigger a specific human emotion, and generates linguistic explanations for the emotional arousal. Despite recent advances in art understanding, pixel-level emotion understanding still faces a dual challenge: first, the subjectivity of emotion makes it difficult for general segmentation models like SAM to adapt to emotion-oriented segmentation tasks; and second, the abstract nature of art expression makes it difficult for captioning models to balance pixel-level semantic understanding and emotion reasoning. To solve the above problems, this paper proposes the Emotion stimuli Segmentation and Explanation Model (EmoSEM) to endow the segmentation model SAM with emotion comprehension capability. First, to enable the model to perform segmentation under the guidance of emotional intent well, we introduce an emotional prompt with a learnable mask token as the conditional input for segmentation decoding. Then, we design an emotion projector to establish the association between emotion and visual features. Next, more importantly, to address emotion-visual stimuli alignment, we develop a lightweight prefix projector, a module that fuses the learned emotional mask with the corresponding emotion into a unified representation compatible with the language model. Finally, we input the joint visual, mask, and emotional tokens into the language model and output the emotional explanations. It ensures that the generated interpretations remain semantically and emotionally coherent with the visual stimuli. The method innovatively realizes end-to-end modeling from low-level pixel features to high-level emotion interpretation, providing the first interpretable fine-grained analysis framework for artistic emotion computing. Extensive experiments validate the effectiveness of our model.
Patch-level Sounding Object Tracking for Audio-Visual Question Answering
Dec 14, 2024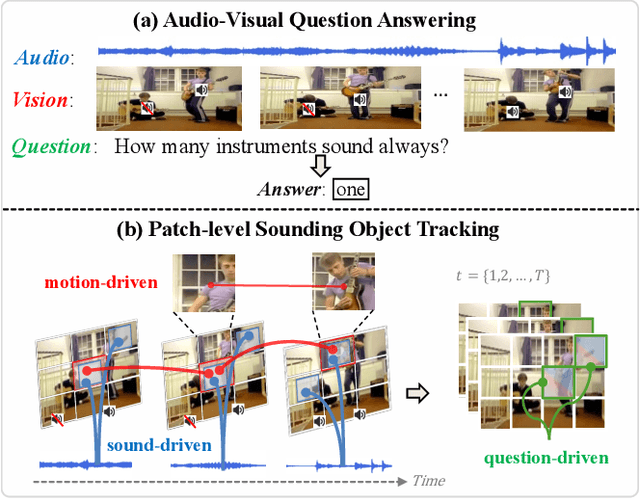
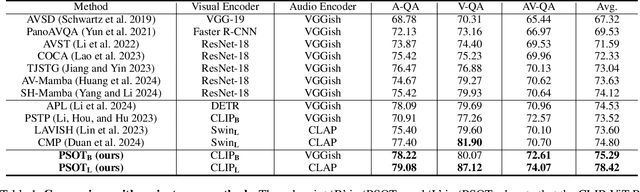
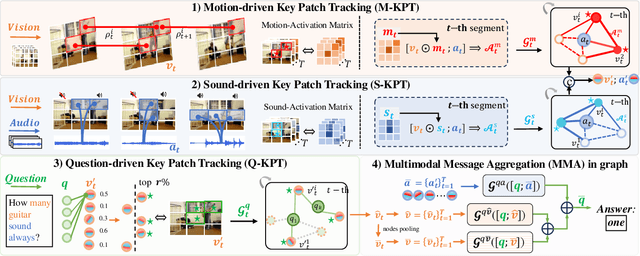
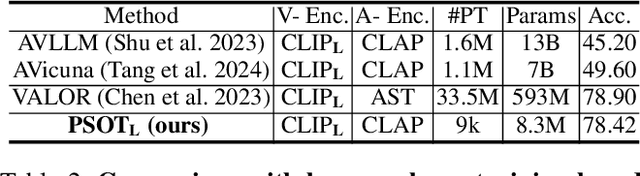
Answering questions related to audio-visual scenes, i.e., the AVQA task, is becoming increasingly popular. A critical challenge is accurately identifying and tracking sounding objects related to the question along the timeline. In this paper, we present a new Patch-level Sounding Object Tracking (PSOT) method. It begins with a Motion-driven Key Patch Tracking (M-KPT) module, which relies on visual motion information to identify salient visual patches with significant movements that are more likely to relate to sounding objects and questions. We measure the patch-wise motion intensity map between neighboring video frames and utilize it to construct and guide a motion-driven graph network. Meanwhile, we design a Sound-driven KPT (S-KPT) module to explicitly track sounding patches. This module also involves a graph network, with the adjacency matrix regularized by the audio-visual correspondence map. The M-KPT and S-KPT modules are performed in parallel for each temporal segment, allowing balanced tracking of salient and sounding objects. Based on the tracked patches, we further propose a Question-driven KPT (Q-KPT) module to retain patches highly relevant to the question, ensuring the model focuses on the most informative clues. The audio-visual-question features are updated during the processing of these modules, which are then aggregated for final answer prediction. Extensive experiments on standard datasets demonstrate the effectiveness of our method, achieving competitive performance even compared to recent large-scale pretraining-based approaches.
Object-aware Adaptive-Positivity Learning for Audio-Visual Question Answering
Dec 20, 2023



This paper focuses on the Audio-Visual Question Answering (AVQA) task that aims to answer questions derived from untrimmed audible videos. To generate accurate answers, an AVQA model is expected to find the most informative audio-visual clues relevant to the given questions. In this paper, we propose to explicitly consider fine-grained visual objects in video frames (object-level clues) and explore the multi-modal relations(i.e., the object, audio, and question) in terms of feature interaction and model optimization. For the former, we present an end-to-end object-oriented network that adopts a question-conditioned clue discovery module to concentrate audio/visual modalities on respective keywords of the question and designs a modality-conditioned clue collection module to highlight closely associated audio segments or visual objects. For model optimization, we propose an object-aware adaptive-positivity learning strategy that selects the highly semantic-matched multi-modal pair as positivity. Specifically, we design two object-aware contrastive loss functions to identify the highly relevant question-object pairs and audio-object pairs, respectively. These selected pairs are constrained to have larger similarity values than the mismatched pairs. The positivity-selecting process is adaptive as the positivity pairs selected in each video frame may be different. These two object-aware objectives help the model understand which objects are exactly relevant to the question and which are making sounds. Extensive experiments on the MUSIC-AVQA dataset demonstrate the proposed method is effective in finding favorable audio-visual clues and also achieves new state-of-the-art question-answering performance.