 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposing and Composing: Towards Efficient Vision-Language Continual Learning via Rank-1 Expert Pool in a Single LoRA
Jan 30, 2026Continual learning (CL) in vision-language models (VLMs) faces significant challenges in improving task adaptation and avoiding catastrophic forgetting. Existing methods usually have heavy inference burden or rely on external knowledge, while Low-Rank Adaptation (LoRA) has shown potential in reducing these issues by enabling parameter-efficient tuning. However, considering directly using LoRA to alleviate the catastrophic forgetting problem is non-trivial, we introduce a novel framework that restructures a single LoRA module as a decomposable Rank-1 Expert Pool. Our method learns to dynamically compose a sparse, task-specific update by selecting from this expert pool, guided by the semantics of the [CLS] token. In addition, we propose an Activation-Guided Orthogonal (AGO) loss that orthogonalizes critical parts of LoRA weights across tasks. This sparse composition and orthogonalization enable fewer parameter updates, resulting in domain-aware learning while minimizing inter-task interference and maintaining downstream task performance. Extensive experiments across multiple settings demonstrate state-of-the-art results in all metrics, surpassing zero-shot upper bounds in generalization. Notably, it reduces trainable parameters by 96.7% compared to the baseline method, eliminating reliance on external datasets or task-ID discriminators. The merged LoRAs retain less weights and incur no inference latency, making our method computationally lightweight.
Dual-Teacher Ensemble Models with Double-Copy-Paste for 3D Semi-Supervised Medical Image Segmentation
Oct 15, 2024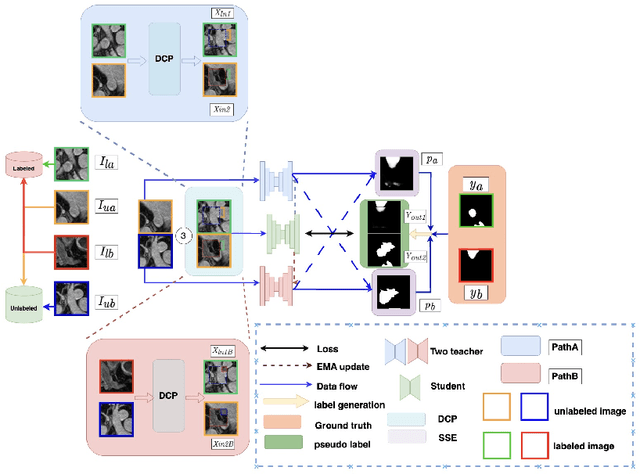
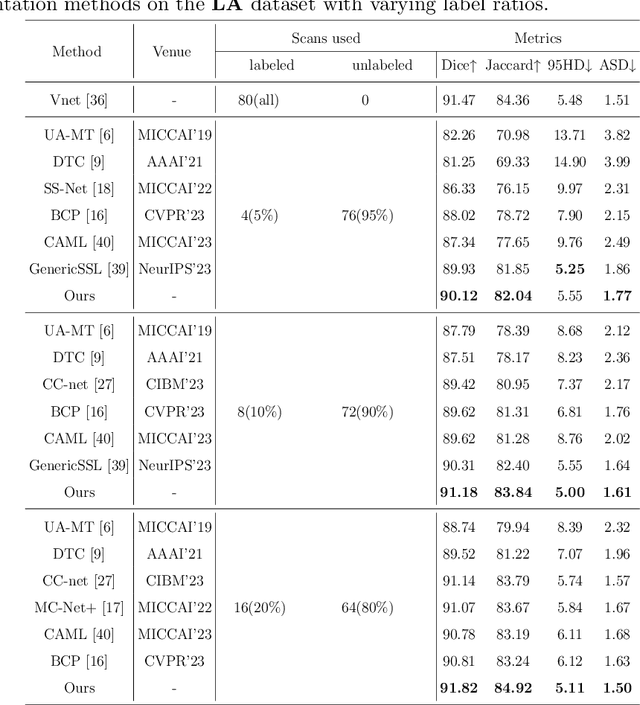
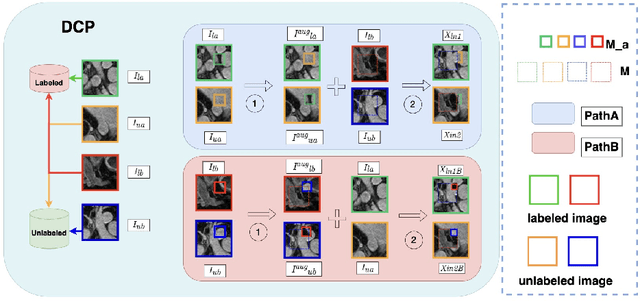
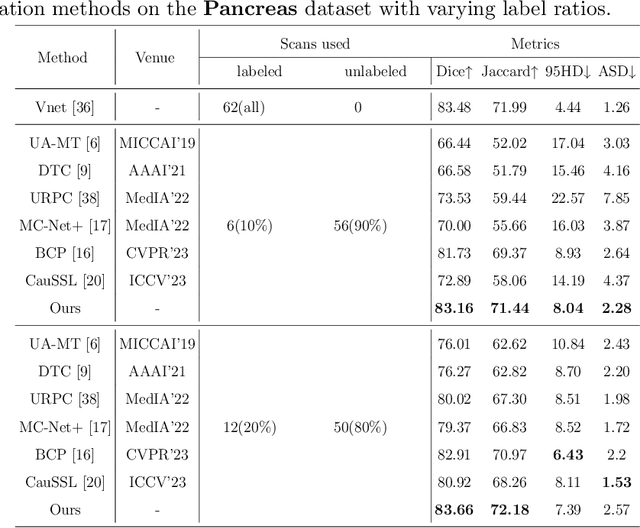
Semi-supervised learning (SSL) techniques address the high labeling costs in 3D medical image segmentation, with the teacher-student model being a common approach. However, using an exponential moving average (EMA) in single-teacher models may cause coupling issues, where the weights of the student and teacher models become similar, limiting the teacher's ability to provide additional knowledge for the student. Dual-teacher models were introduced to address this problem but often neglected the importance of maintaining teacher model diversity, leading to coupling issues among teachers. To address the coupling issue, we incorporate a double-copy-paste (DCP) technique to enhance the diversity among the teachers. Additionally, we introduce the Staged Selective Ensemble (SSE) module, which selects different ensemble methods based on the characteristics of the samples and enables more accurate segmentation of label boundaries, thereby improving the quality of pseudo-labels. Experimental results demonstrate the effectiveness of our proposed method in 3D medical image segmentation tasks. Here is the code link: https://github.com/Fazhan-cs/DCP.