 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaxonomic Class Incremental Learning
Apr 12, 2023The problem of continual learning has attracted rising attention in recent years. However, few works have questioned the commonly used learning setup, based on a task curriculum of random class. This differs significantly from human continual learning, which is guided by taxonomic curricula. In this work, we propose the Taxonomic Class Incremental Learning (TCIL) problem. In TCIL, the task sequence is organized based on a taxonomic class tree. We unify existing approaches to CIL and taxonomic learning as parameter inheritance schemes and introduce a new such scheme for the TCIL learning. This enables the incremental transfer of knowledge from ancestor to descendant class of a class taxonomy through parameter inheritance. Experiments on CIFAR-100 and ImageNet-100 show the effectiveness of the proposed TCIL method, which outperforms existing SOTA methods by 2% in terms of final accuracy on CIFAR-100 and 3% on ImageNet-100.
Learnable Hypergraph Laplacian for Hypergraph Learning
Jun 12, 2021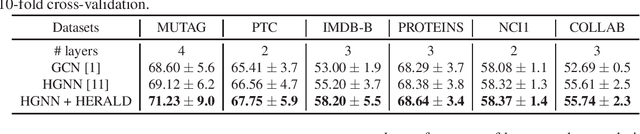
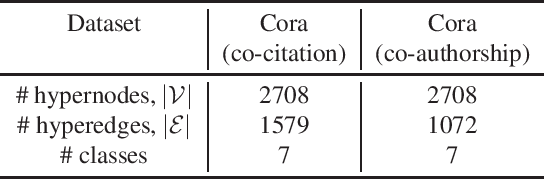

HyperGraph Convolutional Neural Networks (HGCNNs) have demonstrated their potential in modeling high-order relations preserved in graph structured data. However, most existing convolution filters are localized and determined by the pre-defined initial hypergraph topology, neglecting to explore implicit and long-ange relations in real-world data. In this paper, we propose the first learning-based method tailored for constructing adaptive hypergraph structure, termed HypERgrAph Laplacian aDaptor (HERALD), which serves as a generic plug-in-play module for improving the representational power of HGCNNs. Specifically, HERALD adaptively optimizes the adjacency relationship between hypernodes and hyperedges in an end-to-end manner and thus the task-aware hypergraph is learned. Furthermore, HERALD employs the self-attention mechanism to capture the non-local paired-nodes relation. Extensive experiments on various popular hypergraph datasets for node classification and graph classification tasks demonstrate that our approach obtains consistent and considerable performance enhancement, proving its effectiveness and generalization ability.
Diversified Multiscale Graph Learning with Graph Self-Correction
Mar 17, 2021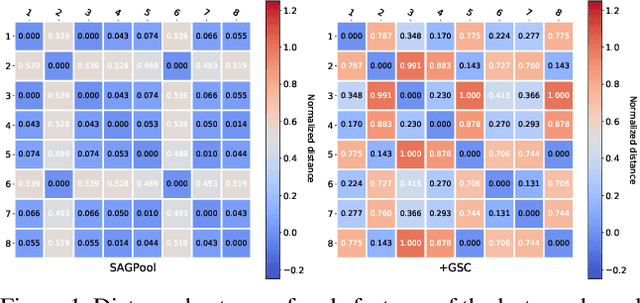
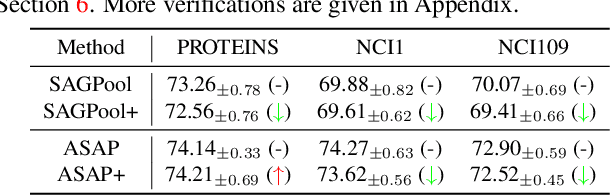
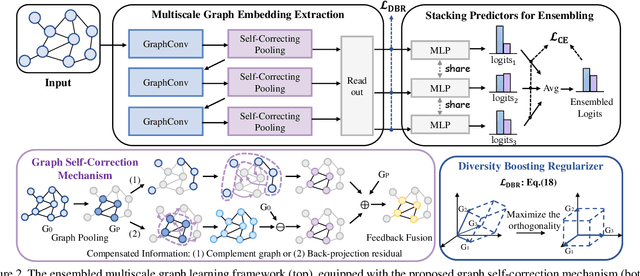
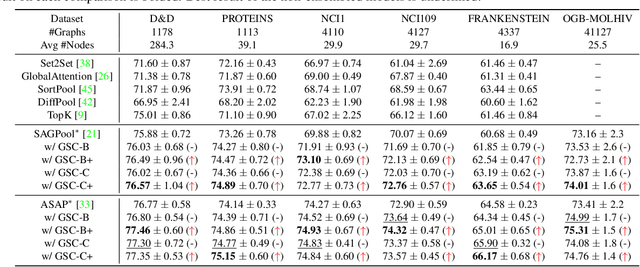
Though the multiscale graph learning techniques have enabled advanced feature extraction frameworks, the classic ensemble strategy may show inferior performance while encountering the high homogeneity of the learnt representation, which is caused by the nature of existing graph pooling methods. To cope with this issue, we propose a diversified multiscale graph learning model equipped with two core ingredients: a graph self-correction (GSC) mechanism to generate informative embedded graphs, and a diversity boosting regularizer (DBR) to achieve a comprehensive characterization of the input graph. The proposed GSC mechanism compensates the pooled graph with the lost information during the graph pooling process by feeding back the estimated residual graph, which serves as a plug-in component for popular graph pooling methods. Meanwhile, pooling methods enhanced with the GSC procedure encourage the discrepancy of node embeddings, and thus it contributes to the success of ensemble learning strategy. The proposed DBR instead enhances the ensemble diversity at the graph-level embeddings by leveraging the interaction among individual classifiers. Extensive experiments on popular graph classification benchmarks show that the proposed GSC mechanism leads to significant improvements over state-of-the-art graph pooling methods. Moreover, the ensemble multiscale graph learning models achieve superior enhancement by combining both GSC and DBR.
On Self-Distilling Graph Neural Network
Nov 04, 2020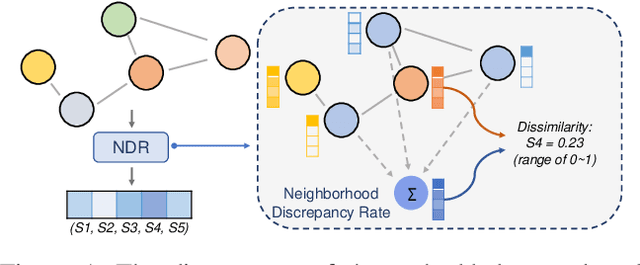
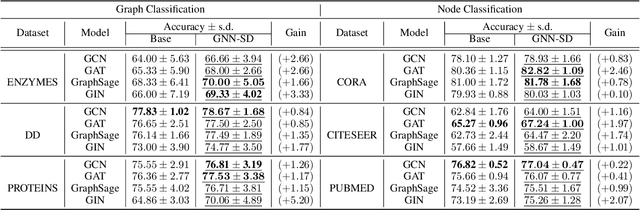
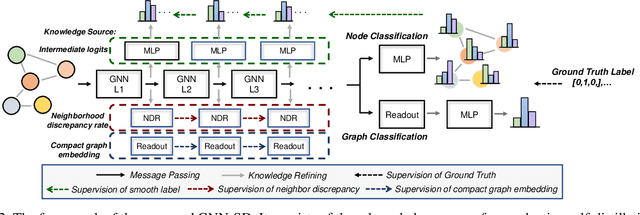
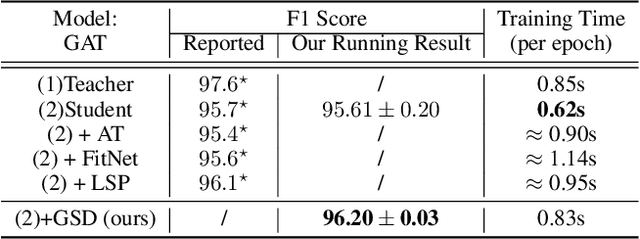
Recently, the teacher-student knowledge distillation framework has demonstrated its potential in training Graph Neural Networks (GNNs). However, due to the difficulty of training deep and wide GNN models, one can not always obtain a satisfactory teacher model for distillation. Furthermore, the inefficient training process of teacher-student knowledge distillation also impedes its applications in GNN models. In this paper, we propose the first teacher-free knowledge distillation framework for GNNs, termed GNN Self-Distillation (GNN-SD), that serves as a drop-in replacement for improving the training process of GNNs.We design three knowledge sources for GNN-SD: neighborhood discrepancy rate (NDR), compact graph embedding and intermediate logits. Notably, serving as a metric of the non-smoothness of the embedded graph, NDR empowers the transferability of knowledge that maintains high neighborhood discrepancy by enforcing consistency between consecutive GNN layers. We conduct exploring analysis to verify that our framework could improve the training dynamics and embedding quality of GNNs. Extensive experiments on various popular GNN models and datasets demonstrate that our approach obtains consistent and considerable performance enhancement, proving its effectiveness and generalization ability.