 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWavetable Synthesis Using CVAE for Timbre Control Based on Semantic Label
Oct 24, 2024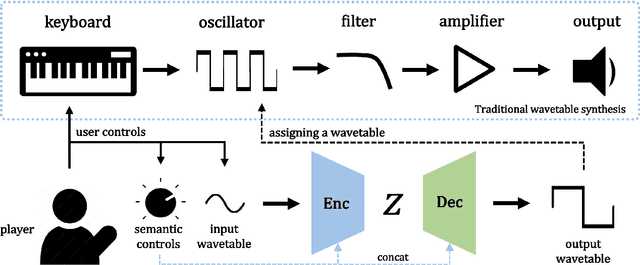
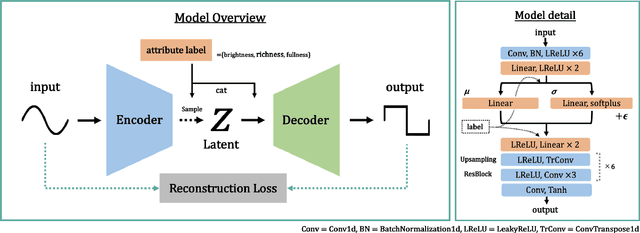
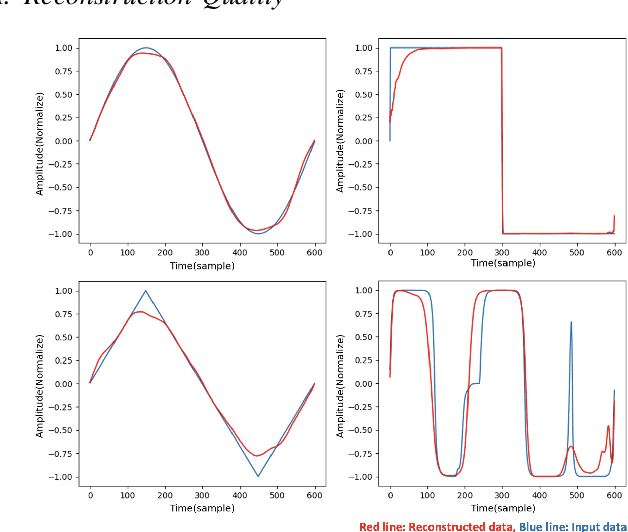
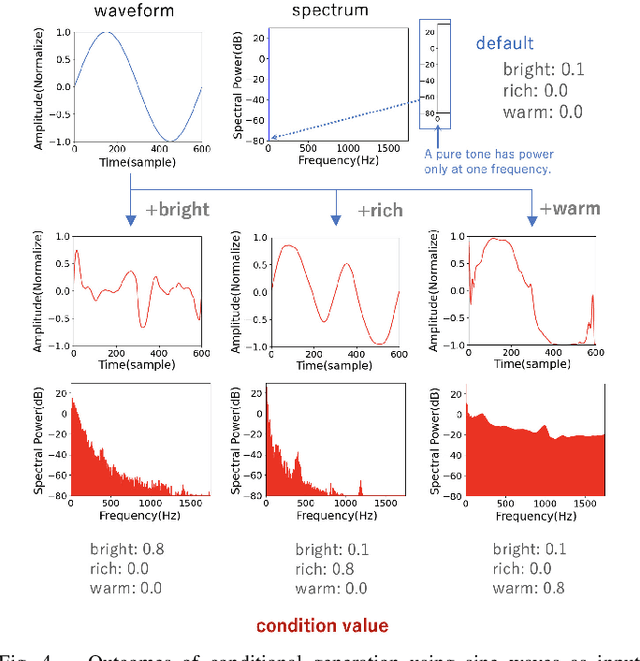
Synthesizers are essential in modern music production. However, their complex timbre parameters, often filled with technical terms, require expertise. This research introduces a method of timbre control in wavetable synthesis that is intuitive and sensible and utilizes semantic labels. Using a conditional variational autoencoder (CVAE), users can select a wavetable and define the timbre with labels such as bright, warm, and rich. The CVAE model, featuring convolutional and upsampling layers, effectively captures the wavetable nuances, ensuring real-time performance owing to their processing in the time domain. Experiments demonstrate that this approach allows for real-time, effective control of the timbre of the wavetable using semantic inputs and aims for intuitive timbre control through data-based semantic control.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
PrimaDNN': A Characteristics-aware DNN Customization for Singing Technique Detection
Jun 25, 2023Professional vocalists modulate their voice timbre or pitch to make their vocal performance more expressive. Such fluctuations are called singing techniques. Automatic detection of singing techniques from audio tracks can be beneficial to understand how each singer expresses the performance, yet it can also be difficult due to the wide variety of the singing techniques. A deep neural network (DNN) model can handle such variety; however, there might be a possibility that considering the characteristics of the data improves the performance of singing technique detection. In this paper, we propose PrimaDNN, a CRNN model with a characteristics-oriented improvement. The features of the model are: 1) input feature representation based on auxiliary pitch information and multi-resolution mel spectrograms, 2) Convolution module based on the Squeeze-and-excitation (SENet) and the Instance normalization. In the results of J-POP singing technique detection, PrimaDNN achieved the best results of 44.9% at the overall macro-F measure, compared to conventional works. We also found that the contribution of each component varies depending on the type of singing technique.
Toward Leveraging Pre-Trained Self-Supervised Frontends for Automatic Singing Voice Understanding Tasks: Three Case Studies
Jun 22, 2023Automatic singing voice understanding tasks, such as singer identification, singing voice transcription, and singing technique classification, benefit from data-driven approaches that utilize deep learning techniques. These approaches work well even under the rich diversity of vocal and noisy samples owing to their representation ability. However, the limited availability of labeled data remains a significant obstacle to achieving satisfactory performance. In recent years, self-supervised learning models (SSL models) have been trained using large amounts of unlabeled data in the field of speech processing and music classification. By fine-tuning these models for the target tasks, comparable performance to conventional supervised learning can be achieved with limited training data. Therefore, in this paper, we investigate the effectiveness of SSL models for various singing voice recognition tasks. We report the results of experiments comparing SSL models for three different tasks (i.e., singer identification, singing voice transcription, and singing technique classification) as initial exploration and aim to discuss these findings. Experimental results show that each SSL model achieves comparable performance and sometimes outperforms compared to state-of-the-art methods on each task. We also conducted a layer-wise analysis to further understand the behavior of the SSL models.
Analysis and Detection of Singing Techniques in Repertoires of J-POP Solo Singers
Nov 15, 2022In this paper, we focus on singing techniques within the scope of music information retrieval research. We investigate how singers use singing techniques using real-world recordings of famous solo singers in Japanese popular music songs (J-POP). First, we built a new dataset of singing techniques. The dataset consists of 168 commercial J-POP songs, and each song is annotated using various singing techniques with timestamps and vocal pitch contours. We also present descriptive statistics of singing techniques on the dataset to clarify what and how often singing techniques appear. We further explored the difficulty of the automatic detection of singing techniques using previously proposed machine learning techniques. In the detection, we also investigate the effectiveness of auxiliary information (i.e., pitch and distribution of label duration), not only providing the baseline. The best result achieves 40.4% at macro-average F-measure on nine-way multi-class detection. We provide the annotation of the dataset and its detail on the appendix website 0 .
Deformable CNN and Imbalance-Aware Feature Learning for Singing Technique Classification
Jun 24, 2022
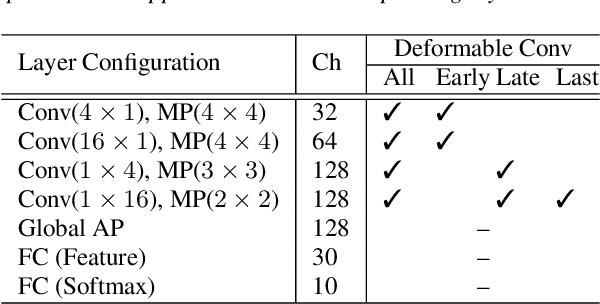


Singing techniques are used for expressive vocal performances by employing temporal fluctuations of the timbre, the pitch, and other components of the voice. Their classification is a challenging task, because of mainly two factors: 1) the fluctuations in singing techniques have a wide variety and are affected by many factors and 2) existing datasets are imbalanced. To deal with these problems, we developed a novel audio feature learning method based on deformable convolution with decoupled training of the feature extractor and the classifier using a class-weighted loss function. The experimental results show the following: 1) the deformable convolution improves the classification results, particularly when it is applied to the last two convolutional layers, and 2) both re-training the classifier and weighting the cross-entropy loss function by a smoothed inverse frequency enhance the classification performance.