 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBATS: A Spectral Biclustering Approach to Single Document Topic Modeling and Segmentation
Aug 05, 2020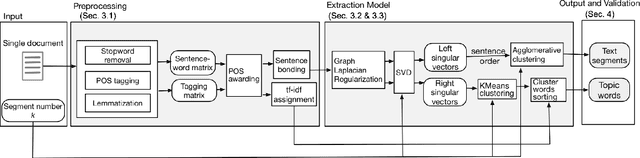

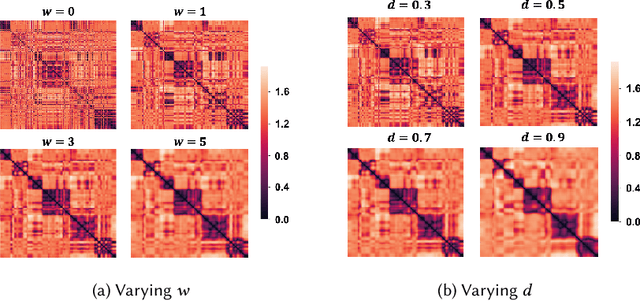
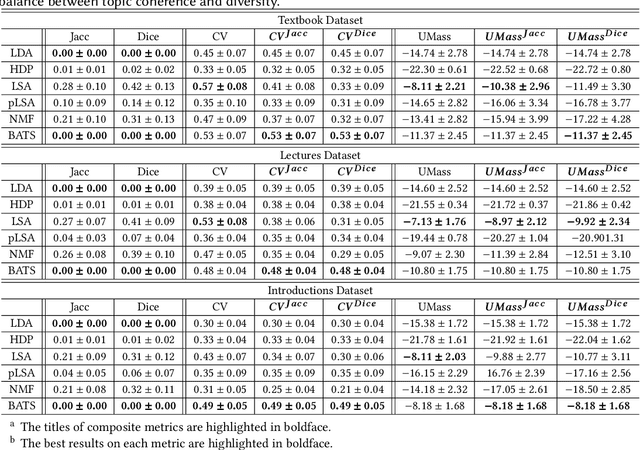
Existing topic modeling and text segmentation methodologies generally require large datasets for training, limiting their capabilities when only small collections of text are available. In this work, we reexamine the inter-related problems of "topic identification" and "text segmentation" for sparse document learning, when there is a single new text of interest. In developing a methodology to handle single documents, we face two major challenges. First is sparse information: with access to only one document, we cannot train traditional topic models or deep learning algorithms. Second is significant noise: a considerable portion of words in any single document will produce only noise and not help discern topics or segments. To tackle these issues, we design an unsupervised, computationally efficient methodology called BATS: Biclustering Approach to Topic modeling and Segmentation. BATS leverages three key ideas to simultaneously identify topics and segment text: (i) a new mechanism that uses word order information to reduce sample complexity, (ii) a statistically sound graph-based biclustering technique that identifies latent structures of words and sentences, and (iii) a collection of effective heuristics that remove noise words and award important words to further improve performance. Experiments on four datasets show that our approach outperforms several state-of-the-art baselines when considering topic coherence, topic diversity, segmentation, and runtime comparison metrics.
A Deep Learning Approach to Behavior-Based Learner Modeling
Jan 23, 2020
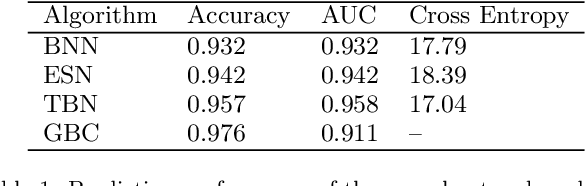
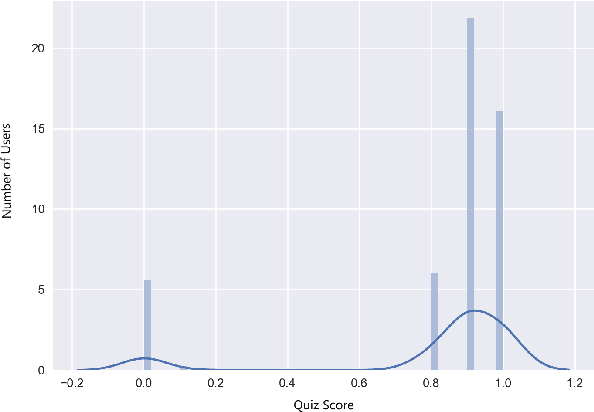
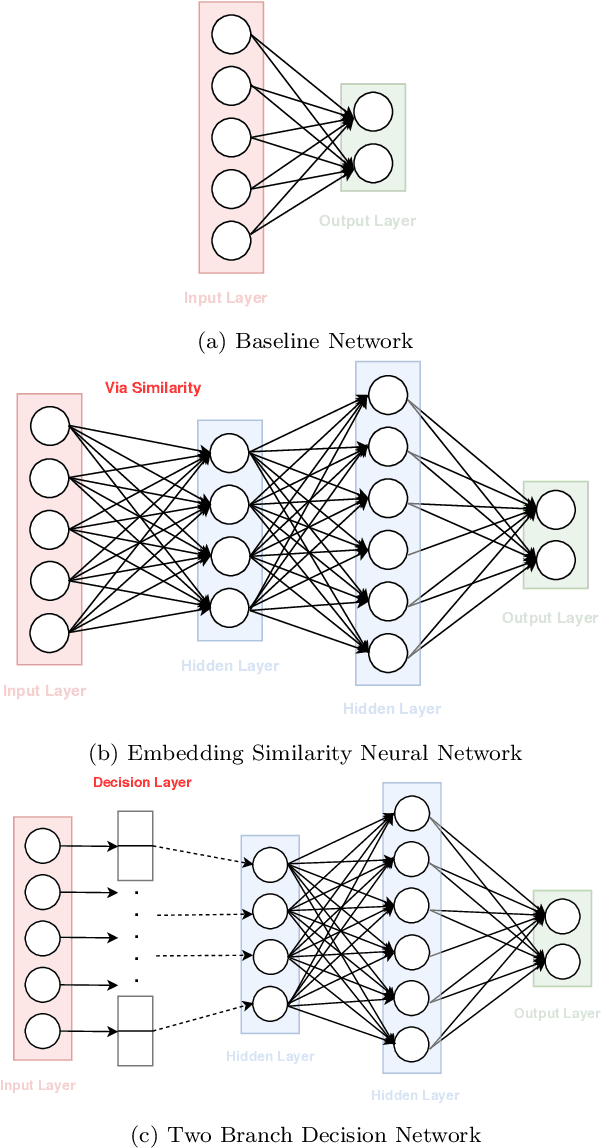
The increasing popularity of e-learning has created demand for improving online education through techniques such as predictive analytics and content recommendations. In this paper, we study learner outcome predictions, i.e., predictions of how they will perform at the end of a course. We propose a novel Two Branch Decision Network for performance prediction that incorporates two important factors: how learners progress through the course and how the content progresses through the course. We combine clickstream features which log every action the learner takes while learning, and textual features which are generated through pre-trained GloVe word embeddings. To assess the performance of our proposed network, we collect data from a short online course designed for corporate training and evaluate both neural network and non-neural network based algorithms on it. Our proposed algorithm achieves 95.7% accuracy and 0.958 AUC score, which outperforms all other models. The results also indicate the combination of behavior features and text features are more predictive than behavior features only and neural network models are powerful in capturing the joint relationship between user behavior and course content.