 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-to-Model Distillation: Data-Efficient Learning Framework
Nov 19, 2024Dataset distillation aims to distill the knowledge of a large-scale real dataset into small yet informative synthetic data such that a model trained on it performs as well as a model trained on the full dataset. Despite recent progress, existing dataset distillation methods often struggle with computational efficiency, scalability to complex high-resolution datasets, and generalizability to deep architectures. These approaches typically require retraining when the distillation ratio changes, as knowledge is embedded in raw pixels. In this paper, we propose a novel framework called Data-to-Model Distillation (D2M) to distill the real dataset's knowledge into the learnable parameters of a pre-trained generative model by aligning rich representations extracted from real and generated images. The learned generative model can then produce informative training images for different distillation ratios and deep architectures. Extensive experiments on 15 datasets of varying resolutions show D2M's superior performance, re-distillation efficiency, and cross-architecture generalizability. Our method effectively scales up to high-resolution 128x128 ImageNet-1K. Furthermore, we verify D2M's practical benefits for downstream applications in neural architecture search.
ATOM: Attention Mixer for Efficient Dataset Distillation
May 02, 2024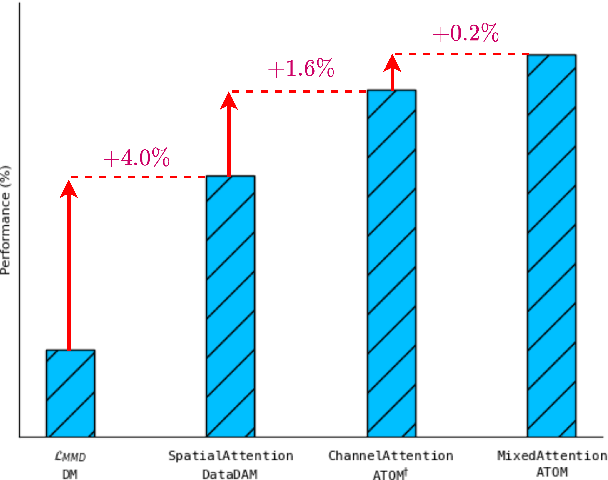

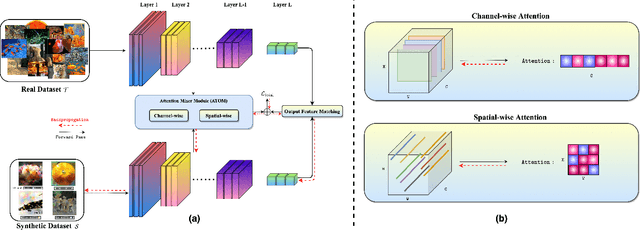

Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.
ProbMCL: Simple Probabilistic Contrastive Learning for Multi-label Visual Classification
Jan 02, 2024



Multi-label image classification presents a challenging task in many domains, including computer vision and medical imaging. Recent advancements have introduced graph-based and transformer-based methods to improve performance and capture label dependencies. However, these methods often include complex modules that entail heavy computation and lack interpretability. In this paper, we propose Probabilistic Multi-label Contrastive Learning (ProbMCL), a novel framework to address these challenges in multi-label image classification tasks. Our simple yet effective approach employs supervised contrastive learning, in which samples that share enough labels with an anchor image based on a decision threshold are introduced as a positive set. This structure captures label dependencies by pulling positive pair embeddings together and pushing away negative samples that fall below the threshold. We enhance representation learning by incorporating a mixture density network into contrastive learning and generating Gaussian mixture distributions to explore the epistemic uncertainty of the feature encoder. We validate the effectiveness of our framework through experimentation with datasets from the computer vision and medical imaging domains. Our method outperforms the existing state-of-the-art methods while achieving a low computational footprint on both datasets. Visualization analyses also demonstrate that ProbMCL-learned classifiers maintain a meaningful semantic topology.
DataDAM: Efficient Dataset Distillation with Attention Matching
Sep 29, 2023



Researchers have long tried to minimize training costs in deep learning while maintaining strong generalization across diverse datasets. Emerging research on dataset distillation aims to reduce training costs by creating a small synthetic set that contains the information of a larger real dataset and ultimately achieves test accuracy equivalent to a model trained on the whole dataset. Unfortunately, the synthetic data generated by previous methods are not guaranteed to distribute and discriminate as well as the original training data, and they incur significant computational costs. Despite promising results, there still exists a significant performance gap between models trained on condensed synthetic sets and those trained on the whole dataset. In this paper, we address these challenges using efficient Dataset Distillation with Attention Matching (DataDAM), achieving state-of-the-art performance while reducing training costs. Specifically, we learn synthetic images by matching the spatial attention maps of real and synthetic data generated by different layers within a family of randomly initialized neural networks. Our method outperforms the prior methods on several datasets, including CIFAR10/100, TinyImageNet, ImageNet-1K, and subsets of ImageNet-1K across most of the settings, and achieves improvements of up to 6.5% and 4.1% on CIFAR100 and ImageNet-1K, respectively. We also show that our high-quality distilled images have practical benefits for downstream applications, such as continual learning and neural architecture search.
* Accepted in International Conference in Computer Vision (ICCV) 2023
A New Probabilistic Distance Metric With Application In Gaussian Mixture Reduction
Jun 12, 2023


This paper presents a new distance metric to compare two continuous probability density functions. The main advantage of this metric is that, unlike other statistical measurements, it can provide an analytic, closed-form expression for a mixture of Gaussian distributions while satisfying all metric properties. These characteristics enable fast, stable, and efficient calculations, which are highly desirable in real-world signal processing applications. The application in mind is Gaussian Mixture Reduction (GMR), which is widely used in density estimation, recursive tracking, and belief propagation. To address this problem, we developed a novel algorithm dubbed the Optimization-based Greedy GMR (OGGMR), which employs our metric as a criterion to approximate a high-order Gaussian mixture with a lower order. Experimental results show that the OGGMR algorithm is significantly faster and more efficient than state-of-the-art GMR algorithms while retaining the geometric shape of the original mixture.
Subclass Knowledge Distillation with Known Subclass Labels
Jul 17, 2022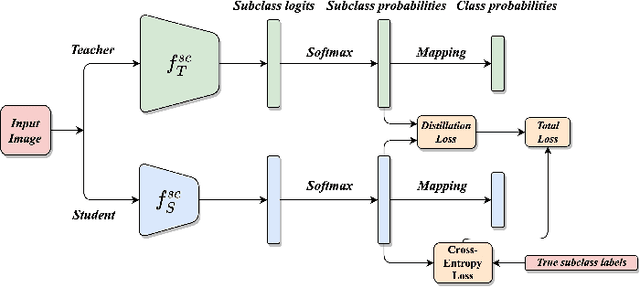
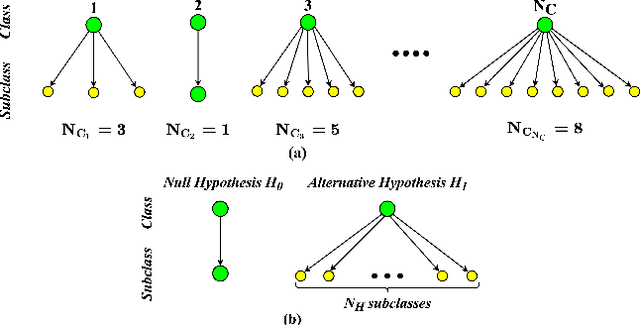
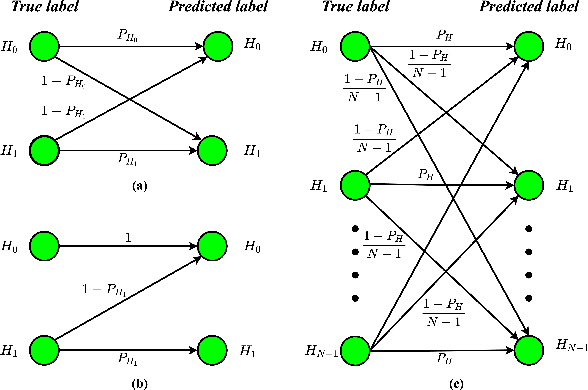
This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection, the amount of information transferred from the teacher to the student is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information of possible subclasses within the classes. To that end, we propose the so-called Subclass Knowledge Distillation (SKD), a process of transferring the knowledge of predicted subclasses from a teacher to a smaller student. Meaningful information that is not in the teacher's class logits but exists in subclass logits (e.g., similarities within classes) will be conveyed to the student through the SKD, which will then boost the student's performance. Analytically, we measure how much extra information the teacher can provide the student via the SKD to demonstrate the efficacy of our work. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. It is a practical problem with two classes and a number of subclasses per class. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low-complexity student trained with the SKD framework achieves an F1-score of 85.05%, an improvement of 1.47%, and a 2.10% gain over the student that is trained with and without conventional knowledge distillation, respectively. The 2.10% F1-score gap between students trained with and without the SKD can be explained by the extra subclass knowledge, i.e., the extra 0.4656 label bits per sample that the teacher can transfer in our experiment.
Evolve To Control: Evolution-based Soft Actor-Critic for Scalable Reinforcement Learning
Jul 24, 2020
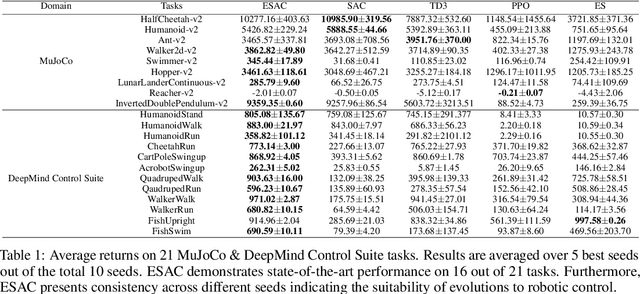
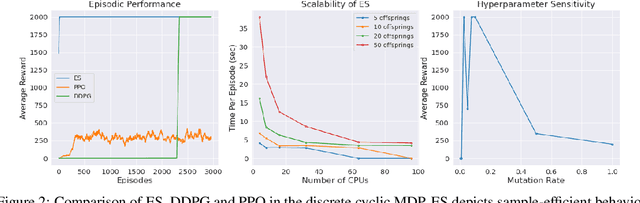
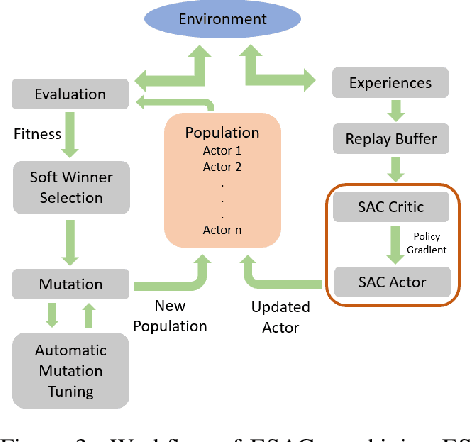
Advances in Reinforcement Learning (RL) have successfully tackled sample efficiency and overestimation bias. However, these methods often fall short of scalable performance. On the other hand, genetic methods provide scalability but depict hyperparameter sensitivity to evolutionary operations. We present the Evolution-based Soft Actor-Critic (ESAC), a scalable RL algorithm. Our contributions are threefold; ESAC (1) abstracts exploration from exploitation by combining Evolution Strategies (ES) with Soft Actor-Critic (SAC), (2) provides dominant skill transfer between offsprings by making use of soft winner selections and genetic crossovers in hindsight and (3) improves hyperparameter sensitivity in evolutions using Automatic Mutation Tuning (AMT). AMT gradually replaces the entropy framework of SAC allowing the population to succeed at the task while acting as randomly as possible, without making use of backpropagation updates. On a range of challenging control tasks consisting of high-dimensional action spaces and sparse rewards, ESAC demonstrates state-of-the-art performance and sample efficiency equivalent to SAC. ESAC demonstrates scalability comparable to ES on the basis of hardware resources and algorithm overhead. A complete implementation of ESAC with notes on reproducibility and videos can be found at the project website https://karush17.github.io/esac-web/.