 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-to-Model Distillation: Data-Efficient Learning Framework
Nov 19, 2024Dataset distillation aims to distill the knowledge of a large-scale real dataset into small yet informative synthetic data such that a model trained on it performs as well as a model trained on the full dataset. Despite recent progress, existing dataset distillation methods often struggle with computational efficiency, scalability to complex high-resolution datasets, and generalizability to deep architectures. These approaches typically require retraining when the distillation ratio changes, as knowledge is embedded in raw pixels. In this paper, we propose a novel framework called Data-to-Model Distillation (D2M) to distill the real dataset's knowledge into the learnable parameters of a pre-trained generative model by aligning rich representations extracted from real and generated images. The learned generative model can then produce informative training images for different distillation ratios and deep architectures. Extensive experiments on 15 datasets of varying resolutions show D2M's superior performance, re-distillation efficiency, and cross-architecture generalizability. Our method effectively scales up to high-resolution 128x128 ImageNet-1K. Furthermore, we verify D2M's practical benefits for downstream applications in neural architecture search.
ATOM: Attention Mixer for Efficient Dataset Distillation
May 02, 2024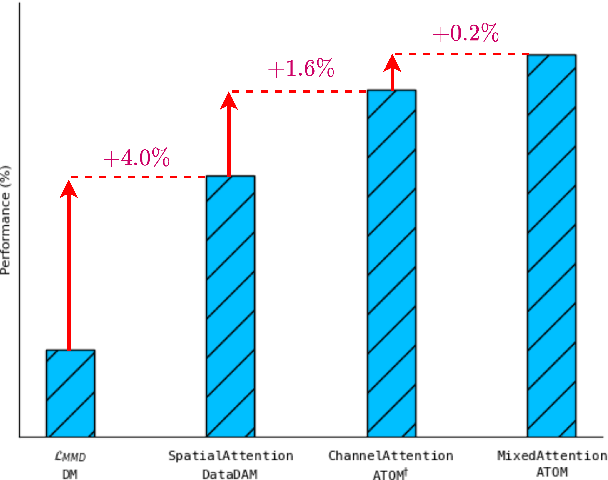

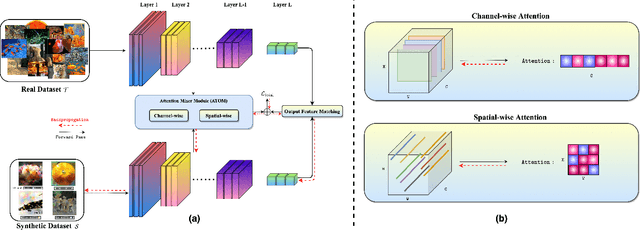

Recent works in dataset distillation seek to minimize training expenses by generating a condensed synthetic dataset that encapsulates the information present in a larger real dataset. These approaches ultimately aim to attain test accuracy levels akin to those achieved by models trained on the entirety of the original dataset. Previous studies in feature and distribution matching have achieved significant results without incurring the costs of bi-level optimization in the distillation process. Despite their convincing efficiency, many of these methods suffer from marginal downstream performance improvements, limited distillation of contextual information, and subpar cross-architecture generalization. To address these challenges in dataset distillation, we propose the ATtentiOn Mixer (ATOM) module to efficiently distill large datasets using a mixture of channel and spatial-wise attention in the feature matching process. Spatial-wise attention helps guide the learning process based on consistent localization of classes in their respective images, allowing for distillation from a broader receptive field. Meanwhile, channel-wise attention captures the contextual information associated with the class itself, thus making the synthetic image more informative for training. By integrating both types of attention, our ATOM module demonstrates superior performance across various computer vision datasets, including CIFAR10/100 and TinyImagenet. Notably, our method significantly improves performance in scenarios with a low number of images per class, thereby enhancing its potential. Furthermore, we maintain the improvement in cross-architectures and applications such as neural architecture search.
DataDAM: Efficient Dataset Distillation with Attention Matching
Sep 29, 2023



Researchers have long tried to minimize training costs in deep learning while maintaining strong generalization across diverse datasets. Emerging research on dataset distillation aims to reduce training costs by creating a small synthetic set that contains the information of a larger real dataset and ultimately achieves test accuracy equivalent to a model trained on the whole dataset. Unfortunately, the synthetic data generated by previous methods are not guaranteed to distribute and discriminate as well as the original training data, and they incur significant computational costs. Despite promising results, there still exists a significant performance gap between models trained on condensed synthetic sets and those trained on the whole dataset. In this paper, we address these challenges using efficient Dataset Distillation with Attention Matching (DataDAM), achieving state-of-the-art performance while reducing training costs. Specifically, we learn synthetic images by matching the spatial attention maps of real and synthetic data generated by different layers within a family of randomly initialized neural networks. Our method outperforms the prior methods on several datasets, including CIFAR10/100, TinyImageNet, ImageNet-1K, and subsets of ImageNet-1K across most of the settings, and achieves improvements of up to 6.5% and 4.1% on CIFAR100 and ImageNet-1K, respectively. We also show that our high-quality distilled images have practical benefits for downstream applications, such as continual learning and neural architecture search.
* Accepted in International Conference in Computer Vision (ICCV) 2023