 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Content Exploration
Oct 10, 2023



Sparse reward environments are known to be challenging for reinforcement learning agents. In such environments, efficient and scalable exploration is crucial. Exploration is a means by which an agent gains information about the environment. We expand on this topic and propose a new intrinsic reward that systemically quantifies exploratory behavior and promotes state coverage by maximizing the information content of a trajectory taken by an agent. We compare our method to alternative exploration based intrinsic reward techniques, namely Curiosity Driven Learning and Random Network Distillation. We show that our information theoretic reward induces efficient exploration and outperforms in various games, including Montezuma Revenge, a known difficult task for reinforcement learning. Finally, we propose an extension that maximizes information content in a discretely compressed latent space which boosts sample efficiency and generalizes to continuous state spaces.
Scope Loss for Imbalanced Classification and RL Exploration
Aug 08, 2023



We demonstrate equivalence between the reinforcement learning problem and the supervised classification problem. We consequently equate the exploration exploitation trade-off in reinforcement learning to the dataset imbalance problem in supervised classification, and find similarities in how they are addressed. From our analysis of the aforementioned problems we derive a novel loss function for reinforcement learning and supervised classification. Scope Loss, our new loss function, adjusts gradients to prevent performance losses from over-exploitation and dataset imbalances, without the need for any tuning. We test Scope Loss against SOTA loss functions over a basket of benchmark reinforcement learning tasks and a skewed classification dataset, and show that Scope Loss outperforms other loss functions.
Energy-based Surprise Minimization for Multi-Agent Value Factorization
Oct 05, 2020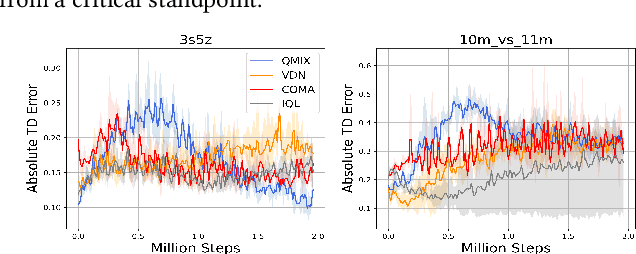
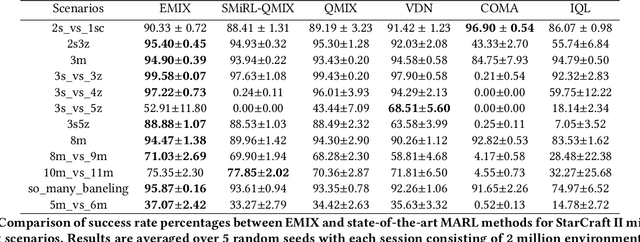
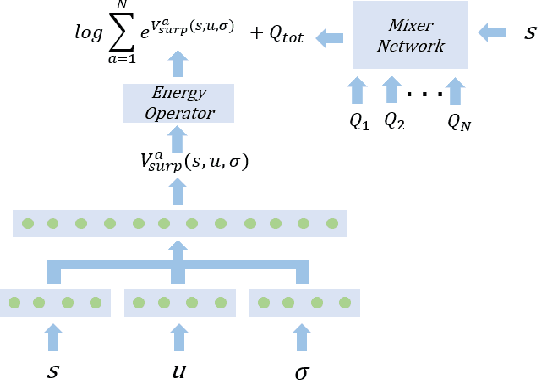
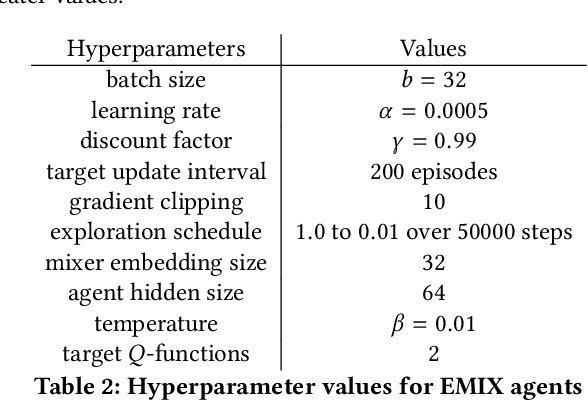
Multi-Agent Reinforcement Learning (MARL) has demonstrated significant success in training decentralised policies in a centralised manner by making use of value factorization methods. However, addressing surprise across spurious states and approximation bias remain open problems for multi-agent settings. We introduce the Energy-based MIXer (EMIX), an algorithm which minimizes surprise utilizing the energy across agents. Our contributions are threefold; (1) EMIX introduces a novel surprise minimization technique across multiple agents in the case of multi-agent partially-observable settings. (2) EMIX highlights the first practical use of energy functions in MARL (to our knowledge) with theoretical guarantees and experiment validations of the energy operator. Lastly, (3) EMIX presents a novel technique for addressing overestimation bias across agents in MARL. When evaluated on a range of challenging StarCraft II micromanagement scenarios, EMIX demonstrates consistent state-of-the-art performance for multi-agent surprise minimization. Moreover, our ablation study highlights the necessity of the energy-based scheme and the need for elimination of overestimation bias in MARL. Our implementation of EMIX and videos of agents are available at https://karush17.github.io/emix-web/.
Evolve To Control: Evolution-based Soft Actor-Critic for Scalable Reinforcement Learning
Jul 24, 2020
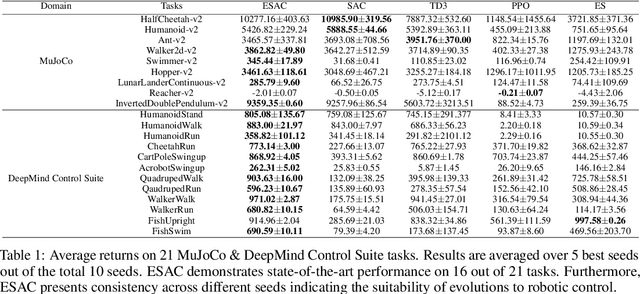
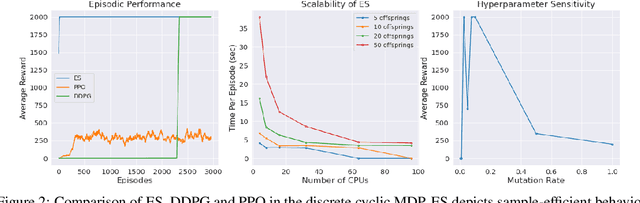
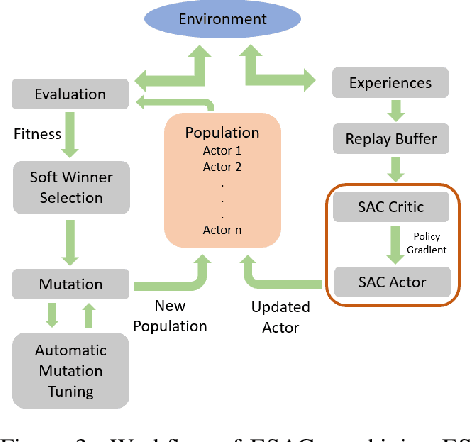
Advances in Reinforcement Learning (RL) have successfully tackled sample efficiency and overestimation bias. However, these methods often fall short of scalable performance. On the other hand, genetic methods provide scalability but depict hyperparameter sensitivity to evolutionary operations. We present the Evolution-based Soft Actor-Critic (ESAC), a scalable RL algorithm. Our contributions are threefold; ESAC (1) abstracts exploration from exploitation by combining Evolution Strategies (ES) with Soft Actor-Critic (SAC), (2) provides dominant skill transfer between offsprings by making use of soft winner selections and genetic crossovers in hindsight and (3) improves hyperparameter sensitivity in evolutions using Automatic Mutation Tuning (AMT). AMT gradually replaces the entropy framework of SAC allowing the population to succeed at the task while acting as randomly as possible, without making use of backpropagation updates. On a range of challenging control tasks consisting of high-dimensional action spaces and sparse rewards, ESAC demonstrates state-of-the-art performance and sample efficiency equivalent to SAC. ESAC demonstrates scalability comparable to ES on the basis of hardware resources and algorithm overhead. A complete implementation of ESAC with notes on reproducibility and videos can be found at the project website https://karush17.github.io/esac-web/.