 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHedging American Put Options with Deep Reinforcement Learning
May 10, 2024This article leverages deep reinforcement learning (DRL) to hedge American put options, utilizing the deep deterministic policy gradient (DDPG) method. The agents are first trained and tested with Geometric Brownian Motion (GBM) asset paths and demonstrate superior performance over traditional strategies like the Black-Scholes (BS) Delta, particularly in the presence of transaction costs. To assess the real-world applicability of DRL hedging, a second round of experiments uses a market calibrated stochastic volatility model to train DRL agents. Specifically, 80 put options across 8 symbols are collected, stochastic volatility model coefficients are calibrated for each symbol, and a DRL agent is trained for each of the 80 options by simulating paths of the respective calibrated model. Not only do DRL agents outperform the BS Delta method when testing is conducted using the same calibrated stochastic volatility model data from training, but DRL agents achieves better results when hedging the true asset path that occurred between the option sale date and the maturity. As such, not only does this study present the first DRL agents tailored for American put option hedging, but results on both simulated and empirical market testing data also suggest the optimality of DRL agents over the BS Delta method in real-world scenarios. Finally, note that this study employs a model-agnostic Chebyshev interpolation method to provide DRL agents with option prices at each time step when a stochastic volatility model is used, thereby providing a general framework for an easy extension to more complex underlying asset processes.
Assisting humans in complex comparisons: automated information comparison at scale
Apr 05, 2024Generative Large Language Models enable efficient analytics across knowledge domains, rivalling human experts in information comparisons. However, the applications of LLMs for information comparisons face scalability challenges due to the difficulties in maintaining information across large contexts and overcoming model token limitations. To address these challenges, we developed the novel Abstractive Summarization \& Criteria-driven Comparison Endpoint (ASC$^2$End) system to automate information comparison at scale. Our system employs Semantic Text Similarity comparisons for generating evidence-supported analyses. We utilize proven data-handling strategies such as abstractive summarization and retrieval augmented generation to overcome token limitations and retain relevant information during model inference. Prompts were designed using zero-shot strategies to contextualize information for improved model reasoning. We evaluated abstractive summarization using ROUGE scoring and assessed the generated comparison quality using survey responses. Models evaluated on the ASC$^2$End system show desirable results providing insights on the expected performance of the system. ASC$^2$End is a novel system and tool that enables accurate, automated information comparison at scale across knowledge domains, overcoming limitations in context length and retrieval.
Energy-based Surprise Minimization for Multi-Agent Value Factorization
Oct 05, 2020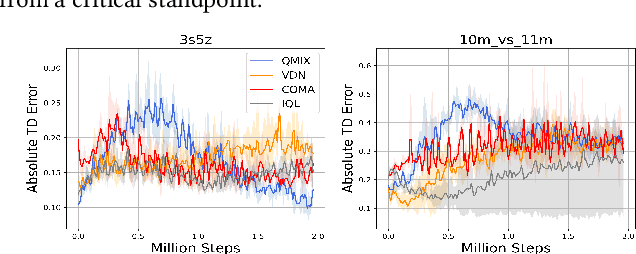
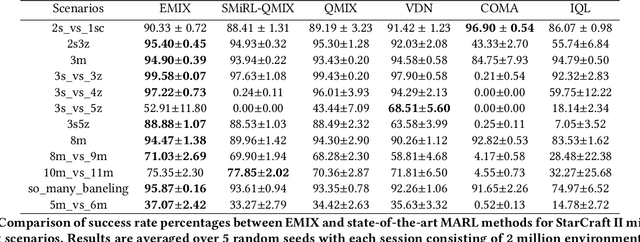
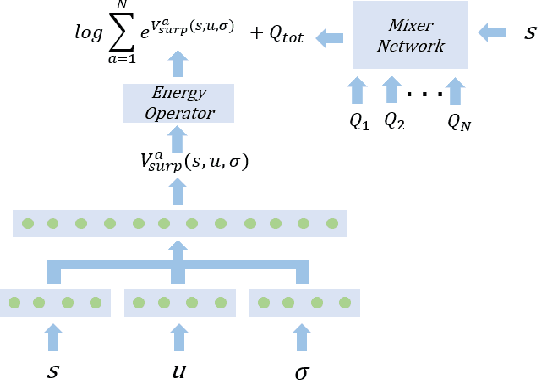
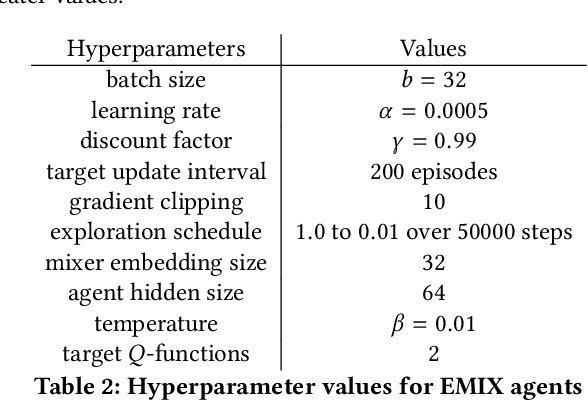
Multi-Agent Reinforcement Learning (MARL) has demonstrated significant success in training decentralised policies in a centralised manner by making use of value factorization methods. However, addressing surprise across spurious states and approximation bias remain open problems for multi-agent settings. We introduce the Energy-based MIXer (EMIX), an algorithm which minimizes surprise utilizing the energy across agents. Our contributions are threefold; (1) EMIX introduces a novel surprise minimization technique across multiple agents in the case of multi-agent partially-observable settings. (2) EMIX highlights the first practical use of energy functions in MARL (to our knowledge) with theoretical guarantees and experiment validations of the energy operator. Lastly, (3) EMIX presents a novel technique for addressing overestimation bias across agents in MARL. When evaluated on a range of challenging StarCraft II micromanagement scenarios, EMIX demonstrates consistent state-of-the-art performance for multi-agent surprise minimization. Moreover, our ablation study highlights the necessity of the energy-based scheme and the need for elimination of overestimation bias in MARL. Our implementation of EMIX and videos of agents are available at https://karush17.github.io/emix-web/.
Implicit Feedback Deep Collaborative Filtering Product Recommendation System
Sep 08, 2020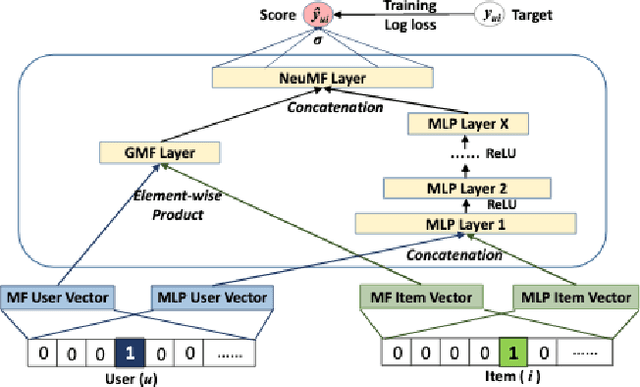


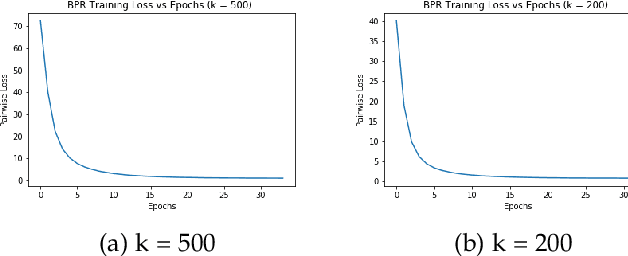
In this paper, several Collaborative Filtering (CF) approaches with latent variable methods were studied using user-item interactions to capture important hidden variations of the sparse customer purchasing behaviors. The latent factors are used to generalize the purchasing pattern of the customers and to provide product recommendations. CF with Neural Collaborative Filtering (NCF) was shown to produce the highest Normalized Discounted Cumulative Gain (NDCG) performance on the real-world proprietary dataset provided by a large parts supply company. Different hyperparameters were tested for applicability in the CF framework. External data sources like click-data and metrics like Clickthrough Rate (CTR) were reviewed for potential extensions to the work presented. The work shown in this paper provides techniques the Company can use to provide product recommendations to enhance revenues, attract new customers, and gain advantages over competitors.