 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubclass Knowledge Distillation with Known Subclass Labels
Paper and Code
Jul 17, 2022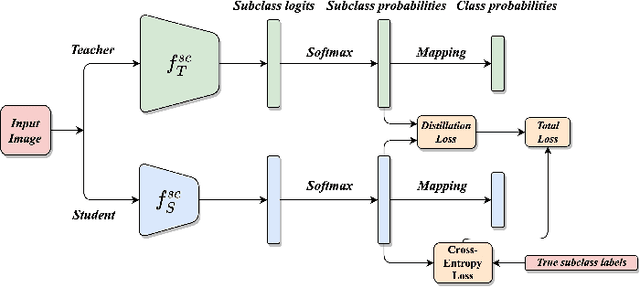
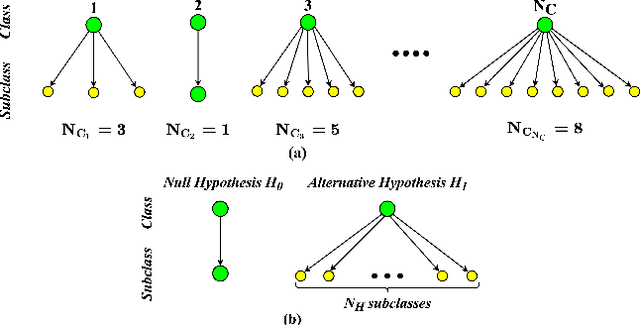
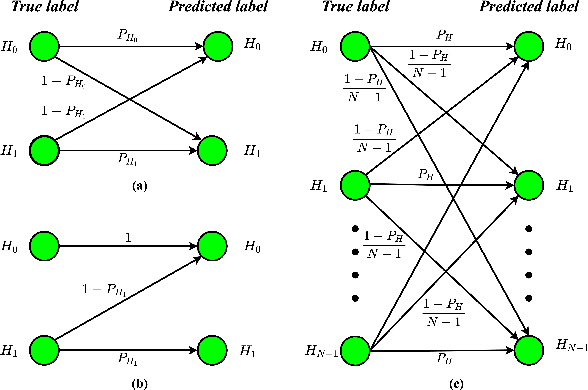
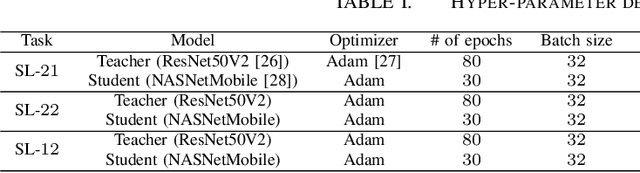
This work introduces a novel knowledge distillation framework for classification tasks where information on existing subclasses is available and taken into consideration. In classification tasks with a small number of classes or binary detection, the amount of information transferred from the teacher to the student is restricted, thus limiting the utility of knowledge distillation. Performance can be improved by leveraging information of possible subclasses within the classes. To that end, we propose the so-called Subclass Knowledge Distillation (SKD), a process of transferring the knowledge of predicted subclasses from a teacher to a smaller student. Meaningful information that is not in the teacher's class logits but exists in subclass logits (e.g., similarities within classes) will be conveyed to the student through the SKD, which will then boost the student's performance. Analytically, we measure how much extra information the teacher can provide the student via the SKD to demonstrate the efficacy of our work. The framework developed is evaluated in clinical application, namely colorectal polyp binary classification. It is a practical problem with two classes and a number of subclasses per class. In this application, clinician-provided annotations are used to define subclasses based on the annotation label's variability in a curriculum style of learning. A lightweight, low-complexity student trained with the SKD framework achieves an F1-score of 85.05%, an improvement of 1.47%, and a 2.10% gain over the student that is trained with and without conventional knowledge distillation, respectively. The 2.10% F1-score gap between students trained with and without the SKD can be explained by the extra subclass knowledge, i.e., the extra 0.4656 label bits per sample that the teacher can transfer in our experiment.