 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning based Joint Active and Passive Beamforming Design for RIS-Assisted MISO Systems
Feb 21, 2022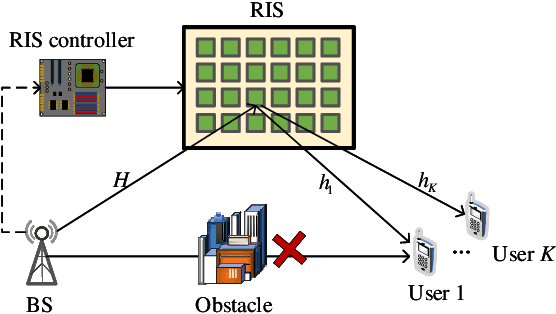
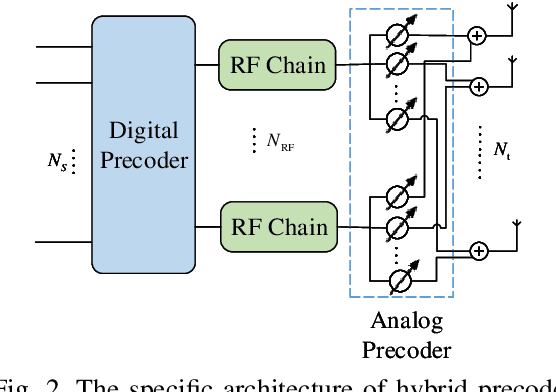

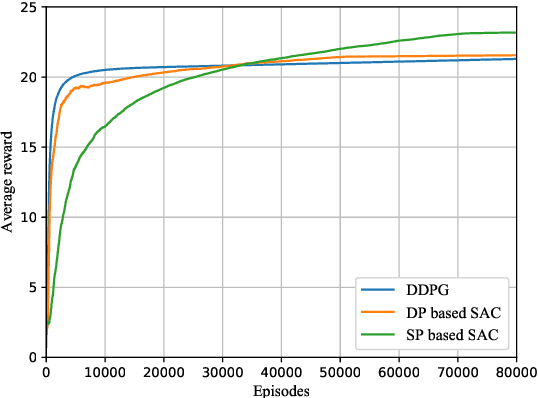
Owing to the unique advantages of low cost and controllability, reconfigurable intelligent surface (RIS) is a promising candidate to address the blockage issue in millimeter wave (mmWave) communication systems, consequently has captured widespread attention in recent years. However, the joint active beamforming and passive beamforming design is an arduous task due to the high computational complexity and the dynamic changes of wireless environment. In this paper, we consider a RIS-assisted multi-user multiple-input single-output (MU-MISO) mmWave system and aim to develop a deep reinforcement learning (DRL) based algorithm to jointly design active hybrid beamformer at the base station (BS) side and passive beamformer at the RIS side. By employing an advanced soft actor-critic (SAC) algorithm, we propose a maximum entropy based DRL algorithm, which can explore more stochastic policies than deterministic policy, to design active analog precoder and passive beamformer simultaneously. Then, the digital precoder is determined by minimum mean square error (MMSE) method. The experimental results demonstrate that our proposed SAC algorithm can achieve better performance compared with conventional optimization algorithm and DRL algorithm.
DRL-based Joint Beamforming and BS-RIS-UE Association Design for RIS-Assisted mmWave Networks
Feb 19, 2022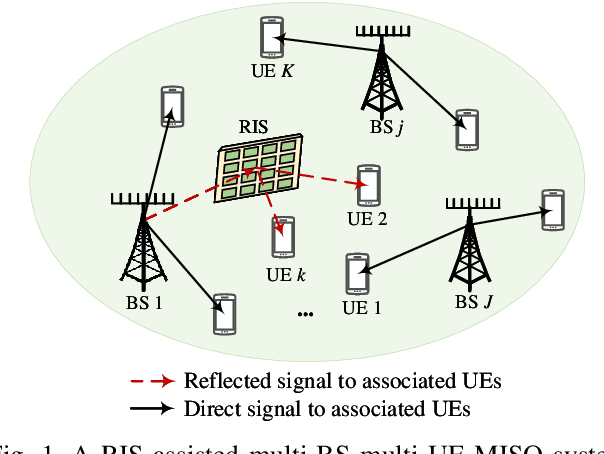
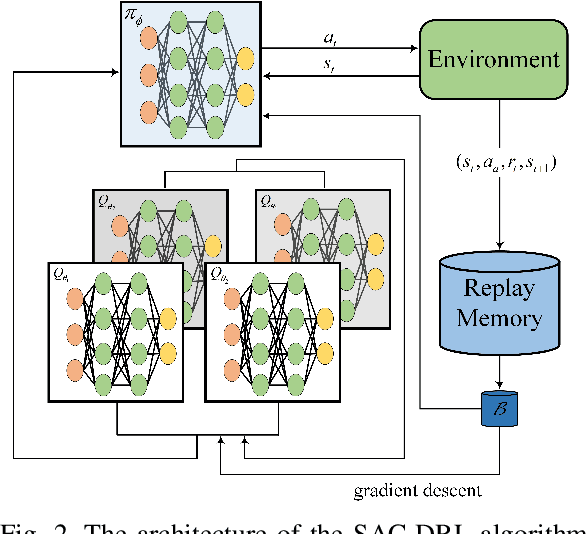
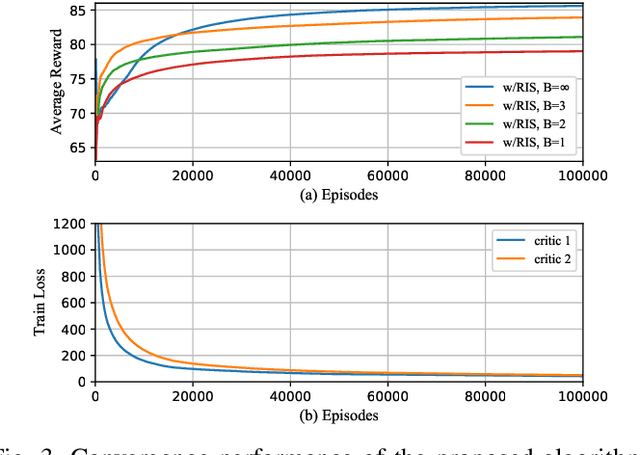
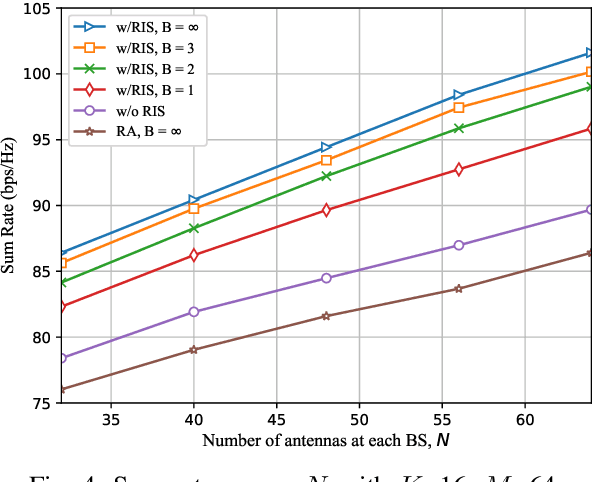
Reconfigurable intelligent surface (RIS) is considered as an extraordinarily promising technology to solve the blockage problem of millimeter wave (mmWave) communications owing to its capable of establishing a reconfigurable wireless propagation. In this paper, we focus on a RIS-assisted mmWave communication network consisting of multiple base stations (BSs) serving a set of user equipments (UEs). Considering the BS-RIS-UE association problem which determines that the RIS should assist which BS and UEs, we joint optimize BS-RIS-UE association and passive beamforming at RIS to maximize the sum-rate of the system. To solve this intractable non-convex problem, we propose a soft actor-critic (SAC) deep reinforcement learning (DRL)-based joint beamforming and BS-RIS-UE association design algorithm, which can learn the best policy by interacting with the environment using less prior information and avoid falling into the local optimal solution by incorporating with the maximization of policy information entropy. The simulation results demonstrate that the proposed SAC-DRL algorithm can achieve significant performance gains compared with benchmark schemes.