 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Trajectory Alignment Coefficient in Two Acts: From Reward Tuning to Reward Learning
Jan 23, 2026The success of reinforcement learning (RL) is fundamentally tied to having a reward function that accurately reflects the task objective. Yet, designing reward functions is notoriously time-consuming and prone to misspecification. To address this issue, our first goal is to understand how to support RL practitioners in specifying appropriate weights for a reward function. We leverage the Trajectory Alignment Coefficient (TAC), a metric that evaluates how closely a reward function's induced preferences match those of a domain expert. To evaluate whether TAC provides effective support in practice, we conducted a human-subject study in which RL practitioners tuned reward weights for Lunar Lander. We found that providing TAC during reward tuning led participants to produce more performant reward functions and report lower cognitive workload relative to standard tuning without TAC. However, the study also underscored that manual reward design, even with TAC, remains labor-intensive. This limitation motivated our second goal: to learn a reward model that maximizes TAC directly. Specifically, we propose Soft-TAC, a differentiable approximation of TAC that can be used as a loss function to train reward models from human preference data. Validated in the racing simulator Gran Turismo 7, reward models trained using Soft-TAC successfully captured preference-specific objectives, resulting in policies with qualitatively more distinct behaviors than models trained with standard Cross-Entropy loss. This work demonstrates that TAC can serve as both a practical tool for guiding reward tuning and a reward learning objective in complex domains.
Lucid Dreaming for Experience Replay: Refreshing Past States with the Current Policy
Sep 29, 2020

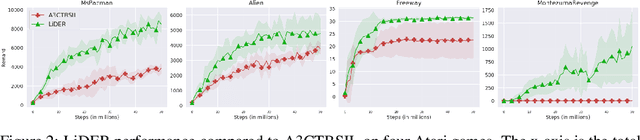

Experience replay (ER) improves the data efficiency of off-policy reinforcement learning (RL) algorithms by allowing an agent to store and reuse its past experiences in a replay buffer. While many techniques have been proposed to enhance ER by biasing how experiences are sampled from the buffer, thus far they have not considered strategies for refreshing experiences inside the buffer. In this work, we introduce Lucid Dreaming for Experience Replay (LiDER), a conceptually new framework that allows replay experiences to be refreshed by leveraging the agent's current policy. LiDER 1) moves an agent back to a past state; 2) lets the agent try following its current policy to execute different actions---as if the agent were "dreaming" about the past, but is aware of the situation and can control the dream to encounter new experiences; and 3) stores and reuses the new experience if it turned out better than what the agent previously experienced, i.e., to refresh its memories. LiDER is designed to be easily incorporated into off-policy, multi-worker RL algorithms that use ER; we present in this work a case study of applying LiDER to an actor-critic based algorithm. Results show LiDER consistently improves performance over the baseline in four Atari 2600 games. Our open-source implementation of LiDER and the data used to generate all plots in this paper are available at github.com/duyunshu/lucid-dreaming-for-exp-replay.
Jointly Pre-training with Supervised, Autoencoder, and Value Losses for Deep Reinforcement Learning
Apr 03, 2019

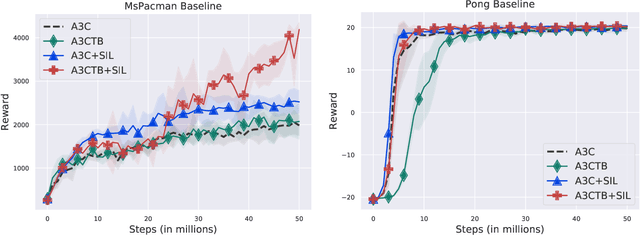
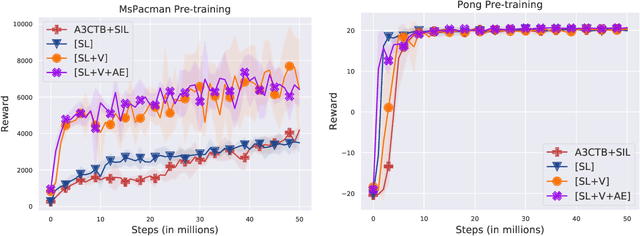
Deep Reinforcement Learning (DRL) algorithms are known to be data inefficient. One reason is that a DRL agent learns both the feature and the policy tabula rasa. Integrating prior knowledge into DRL algorithms is one way to improve learning efficiency since it helps to build helpful representations. In this work, we consider incorporating human knowledge to accelerate the asynchronous advantage actor-critic (A3C) algorithm by pre-training a small amount of non-expert human demonstrations. We leverage the supervised autoencoder framework and propose a novel pre-training strategy that jointly trains a weighted supervised classification loss, an unsupervised reconstruction loss, and an expected return loss. The resulting pre-trained model learns more useful features compared to independently training in supervised or unsupervised fashion. Our pre-training method drastically improved the learning performance of the A3C agent in Atari games of Pong and MsPacman, exceeding the performance of the state-of-the-art algorithms at a much smaller number of game interactions. Our method is light-weight and easy to implement in a single machine. For reproducibility, our code is available at github.com/gabrieledcjr/DeepRL/tree/A3C-ALA2019
Pre-training with Non-expert Human Demonstration for Deep Reinforcement Learning
Dec 21, 2018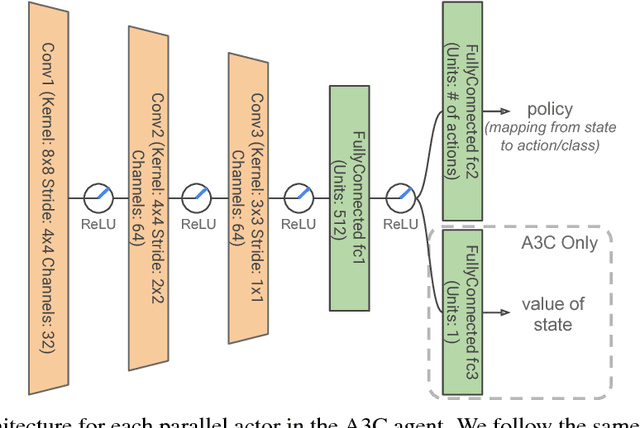
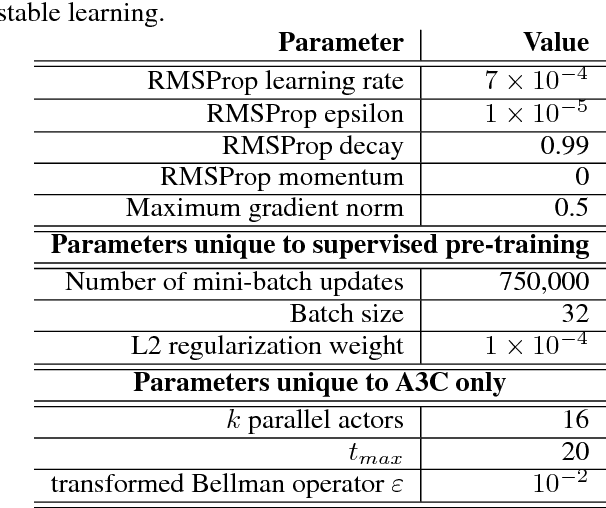


Deep reinforcement learning (deep RL) has achieved superior performance in complex sequential tasks by using deep neural networks as function approximators to learn directly from raw input images. However, learning directly from raw images is data inefficient. The agent must learn feature representation of complex states in addition to learning a policy. As a result, deep RL typically suffers from slow learning speeds and often requires a prohibitively large amount of training time and data to reach reasonable performance, making it inapplicable to real-world settings where data is expensive. In this work, we improve data efficiency in deep RL by addressing one of the two learning goals, feature learning. We leverage supervised learning to pre-train on a small set of non-expert human demonstrations and empirically evaluate our approach using the asynchronous advantage actor-critic algorithms (A3C) in the Atari domain. Our results show significant improvements in learning speed, even when the provided demonstration is noisy and of low quality.
Adapting Auxiliary Losses Using Gradient Similarity
Dec 05, 2018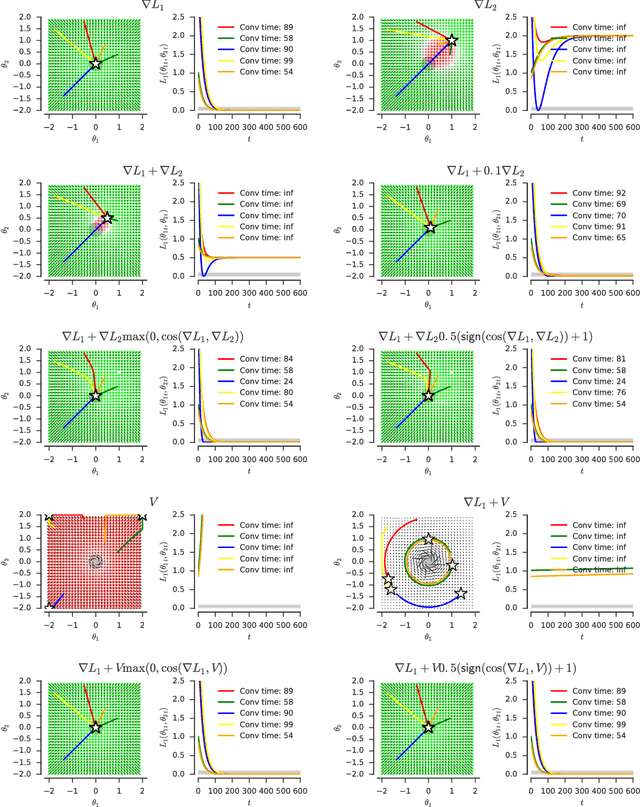
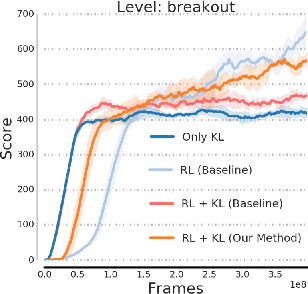
One approach to deal with the statistical inefficiency of neural networks is to rely on auxiliary losses that help to build useful representations. However, it is not always trivial to know if an auxiliary task will be helpful for the main task and when it could start hurting. We propose to use the cosine similarity between gradients of tasks as an adaptive weight to detect when an auxiliary loss is helpful to the main loss. We show that our approach is guaranteed to converge to critical points of the main task and demonstrate the practical usefulness of the proposed algorithm in a few domains: multi-task supervised learning on subsets of ImageNet, reinforcement learning on gridworld, and reinforcement learning on Atari games.
Pre-training Neural Networks with Human Demonstrations for Deep Reinforcement Learning
Sep 12, 2017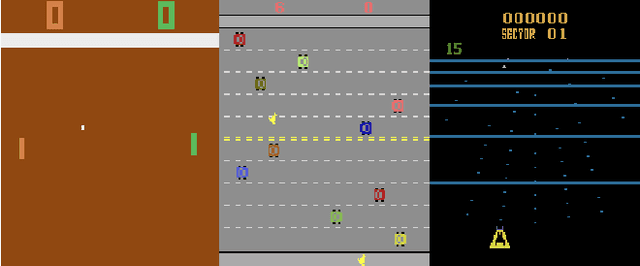

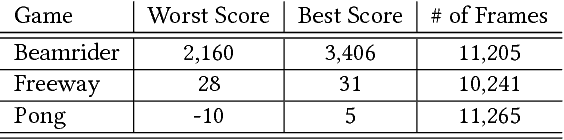
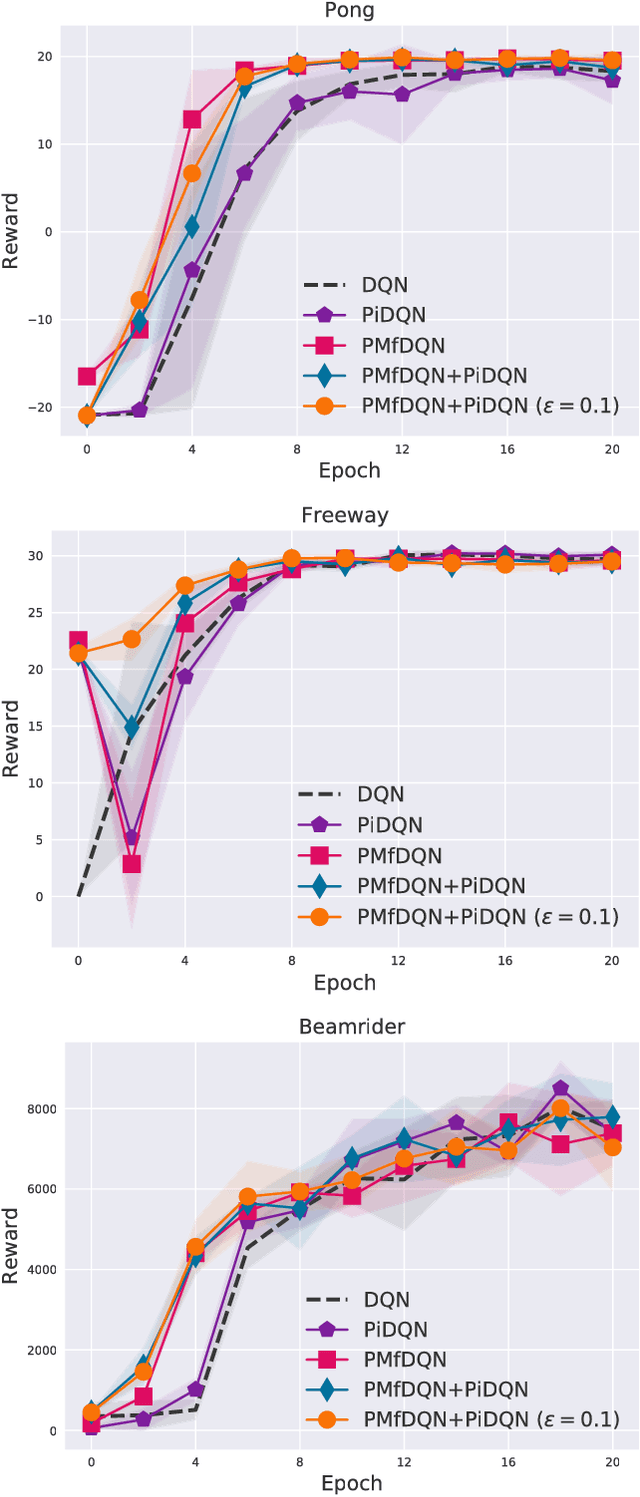
Deep reinforcement learning (deep RL) has achieved superior performance in complex sequential tasks by using a deep neural network as its function approximator and by learning directly from raw images. A drawback of using raw images is that deep RL must learn the state feature representation from the raw images in addition to learning a policy. As a result, deep RL can require a prohibitively large amount of training time and data to reach reasonable performance, making it difficult to use deep RL in real-world applications, especially when data is expensive. In this work, we speed up training by addressing half of what deep RL is trying to solve --- learning features. Our approach is to learn some of the important features by pre-training deep RL network's hidden layers via supervised learning using a small set of human demonstrations. We empirically evaluate our approach using deep Q-network (DQN) and asynchronous advantage actor-critic (A3C) algorithms on the Atari 2600 games of Pong, Freeway, and Beamrider. Our results show that: 1) pre-training with human demonstrations in a supervised learning manner is better at discovering features relative to pre-training naively in DQN, and 2) initializing a deep RL network with a pre-trained model provides a significant improvement in training time even when pre-training from a small number of human demonstrations.